
Imagine it's the early 2000s, and you're a developer with a bold idea. You want to test your software not in a safe, controlled environment but right where the action is: the production environment. This is where real users interact with your system. Back then, suggesting something like this might have gotten you some strange looks from your bosses. But now, testing in the real world is not just okay; it's often recommended.
Why the big change? A few reasons stand out. Systems today are more complex than ever, pushing us to innovate faster and ensure our services are both reliable and strong. The rise of cloud technology, microservices, and distributed systems has changed the game. We've had to adapt our methods and mindsets accordingly.
Our goal now is to make systems that can handle anything—be it a slowdown or a full-blown outage. Enter Chaos Engineering.
In this issue, we dive into what chaos engineering is all about. We'll break down its key principles, how it's practiced, and examples from the real world. You'll learn how causing a bit of controlled chaos can actually help find and fix weaknesses before they become major problems.
Prepare to see how embracing chaos can lead to stronger, more reliable systems. Let's get started!
So, what exactly is chaos engineering? It's a way to deal with unexpected issues in software development and keep systems up and running. Some folks might think that a server running an app will continue without a hitch forever. Others believe that problems are just part of the deal and that downtime is inevitable.
Chaos engineering strikes a balance between these views. It recognizes that things can go wrong but asserts that we can take steps to prevent these issues from impacting our systems and the performance of our apps.
This approach involves experimenting on our live, production systems to identify weak spots and areas that aren't as reliable as they should be. It's about measuring how much we trust our system's resilience and working to boost that confidence
However, it's important to understand that being 100% sure nothing will go wrong is unrealistic. Through chaos engineering, we intentionally introduce unexpected events to uncover vulnerabilities. These events can vary widely, such as taking down a server randomly, disrupting a data center, or tampering with load balancers and application replicas.
In short, chaos engineering is about designing experiments that rigorously test our systems' robustness.
There are many ways to describe chaos engineering, but here's a definition that captures its essence well, sourced from https://principlesofchaos.org/.
“Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.”
This definition highlights the core objective of chaos engineering: to ensure our systems can handle the unpredictable nature of real-world operations.
When we talk about ensuring our systems run smoothly, two concepts often come up: performance engineering and chaos engineering. Let's discuss what sets these two apart and how they might overlap.
Many developers are already familiar with performance engineering, which is in the same family as DevOps. It involves using a combination of tools, processes, and technologies to monitor our system's performance and make continuous improvements. This includes conducting various types of testing, such as load, stress, and endurance tests, all aimed at boosting the performance of our applications.
On the flip side, chaos engineering is about intentionally breaking things. Yes, this includes stress testing, but it's more about observing how systems respond under unexpected stress. Stress testing could be seen as a form of chaos experiment. So, one way to look at it is to consider performance engineering as a subset of chaos engineering or the other way around, depending on how you apply these practices.
Another way to view these two is as distinct disciplines within an organization. One team might focus solely on conducting chaos experiments and learning from the failures, while another might immerse itself in performance engineering tasks like testing and monitoring. Depending on the structure of the organization, the skill sets of the team, and various other factors, we might have separate teams for each discipline or one team that tackles both.
Let's consider an example to better understand chaos engineering. Imagine we have a system with a load balancer that directs requests to web servers. These servers then connect to a payment service, which, in turn, interacts with a third-party API and a cache service, all located in Availability Zone A. If the payment service fails to communicate with the third-party API or the cache, requests need to be rerouted to Availability Zone B to maintain high availability.
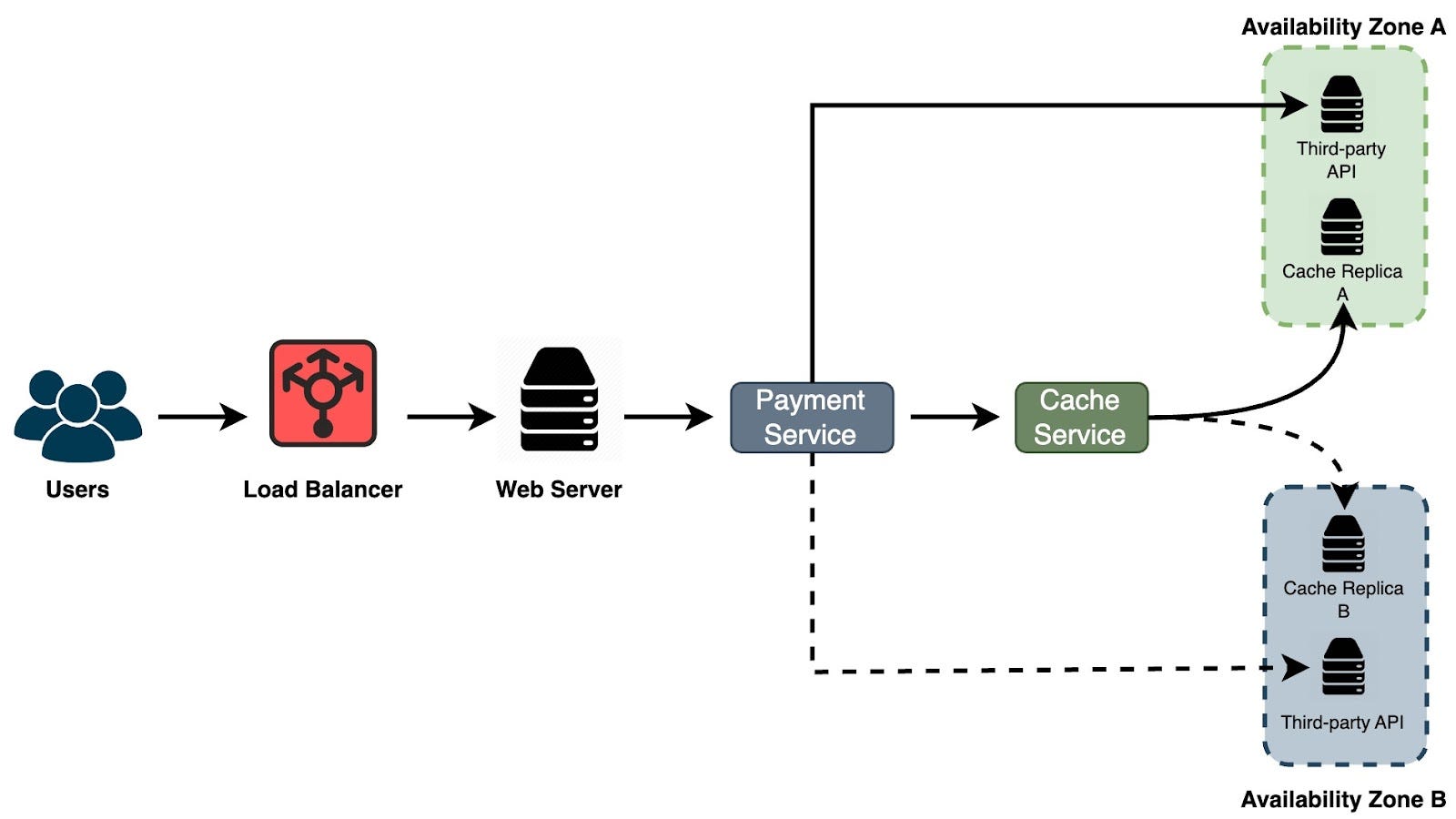
This setup is common in cloud-based e-commerce platforms, where services are strategically distributed across different zones for added resilience. The challenge lies in ensuring that if Zone A experiences downtime, the system can seamlessly switch to Zone B. Chaos engineering plays an important role here. By deliberately injecting controlled disruptions, teams can identify weak spots, fine-tune failure responses, and continually enhance the system's resilience and availability.
Chaos engineering isn't just about breaking things to see what happens. It's a methodical approach aimed at strengthening our systems. Let's walk through the six key steps involved in conducting chaos engineering experiments.
This is where it all begins. Formulating a hypothesis is to make an educated guess about our system's behavior under stress. For instance, we might hypothesize that if our cache service goes down, we can reroute requests to a backup zone to keep everything running smoothly. It's crucial to base our hypotheses on a solid understanding of our system's architecture and dependencies.
Once we have our hypothesis, we design an experiment to test it. This step involves careful planning to ensure that our experiment is controlled and its impact can be accurately measured. In our example, our experiment might involve simulating a scenario where the cache service in one zone is intentionally disabled. It's about setting the stage for a controlled disruption that mimics real-world conditions as closely as possible.
After designing our experiment, we move on to the chaos injection phase. This is where we deliberately introduce the planned disruption into our system. Continuing with our example, this would mean shutting down the cache service in the specified zone. It's vital to monitor the system closely during this phase to ensure the experiment remains controlled and to prevent unintended consequences.
As the chaos unfolds, observing the system's response is critical. Monitoring and logging tools allow us to track the system's behavior in real-time and collect data for analysis. This step helps us gather evidence on whether our system reacts as expected or if there are unexpected behaviors or failures.
With data in hand, we analyze how the system coped with the chaos. This analysis helps us identify weaknesses, resilience gaps, and areas for improvement. If our system fails to reroute requests as hypothesized, we need to understand why and how we can fix it. This step is about turning observations into actionable insights.
Finally, we close the loop with learning and iteration. The insights gained from our experiments inform changes and improvements to our system's infrastructure or processes. It's a repeated process of applying lessons learned to make our system more resilient against future disruptions.
While the steps to perform chaos engineering experiments lay out a roadmap for testing, it's the guiding principles that ensure these tests are effective, safe, and yield valuable insights. Here are some fundamental principles you should follow when practicing chaos engineering.

Short-term observations might not reveal the full impact of chaos on your system. It's crucial to measure the effects over an extended period, as issues may not manifest immediately. Sometimes, the consequences of introducing chaos could take hours or even days to become evident. This principle ensures a lack of immediate issues does not falsely reassure us.
Chaos engineering isn't about causing random disruptions. Instead, it focuses on testing specific hypotheses about how and where our system might fail. Before starting any experiment, clearly define what you're testing and what outcomes you expect. This approach ensures that experiments are purposeful and that their results are actionable.
The most effective chaos experiments simulate scenarios that could happen in the real world. This includes events like server crashes, hard drive failures, network outages, and application errors. Conducting these experiments regularly or continuously to prepare the system for actual disruptions.
Starting small is key to effective chaos engineering. By initially limiting the impact (or "blast radius") of the experiments, we reduce the risk of causing significant disruptions to the service. This cautious approach allows us to gauge the resilience of the system without overwhelming it. As we gain confidence in the system's ability to handle disruptions, we can gradually expand the scope of the experiments.
The ability to quickly revert changes is essential in chaos engineering. Despite careful planning, experiments can produce unexpected results. A robust rollback plan ensures that we can quickly restore the system to a stable state if an experiment goes awry. This safety net is critical for mitigating the risk of prolonged disruptions to the service.
Chaos engineering might seem like a high-risk strategy at first glance, but when executed correctly, it's a powerful method for enhancing system resilience. Let's look at how some of the biggest names in tech have employed chaos engineering to fortify their systems against unexpected disruptions.
Netflix, a pioneer in chaos engineering, developed a tool known as Chaos Monkey. This tool intentionally disrupts Netflix's production environment by randomly terminating virtual machine instances. The objective? To design services that are resilient to instance failures. Chaos Monkey's proactive approach allows Netflix to continuously test and improve its system's resilience, ensuring that the platform can handle unexpected failures without a significant impact on user experience.

Amazon uses chaos engineering practices to test the resilience of its vast network of services. One notable tool is Chaos Gorilla, part of the Simian Army suite developed by Netflix, which simulates large-scale outages. This kind of testing is crucial for Amazon. It uncovers and addresses potential weaknesses in its infrastructure and enhances the robustness and reliability of its cloud services.

Microsoft Azure uses chaos engineering to maintain the reliability and availability of its cloud platform. Through the use of Chaos Studio, Azure engineers simulate various failure scenarios, including hardware malfunctions and network disruptions. Regular testing with Chaos Studio enables Azure to identify potential vulnerabilities and implement fixes proactively.

Spotify, known for its music streaming service, also adopts chaos engineering to ensure the reliability of its infrastructure. The company developed its own chaos engineering tool named Chaos Kong. This tool allows Spotify's engineering team to simulate failures across its distributed systems, testing how well they can withstand disruptions. The insights gained from these experiments help Spotify to continually refine and strengthen its services.

Here's a closer look at some of the key advantages of chaos engineering:
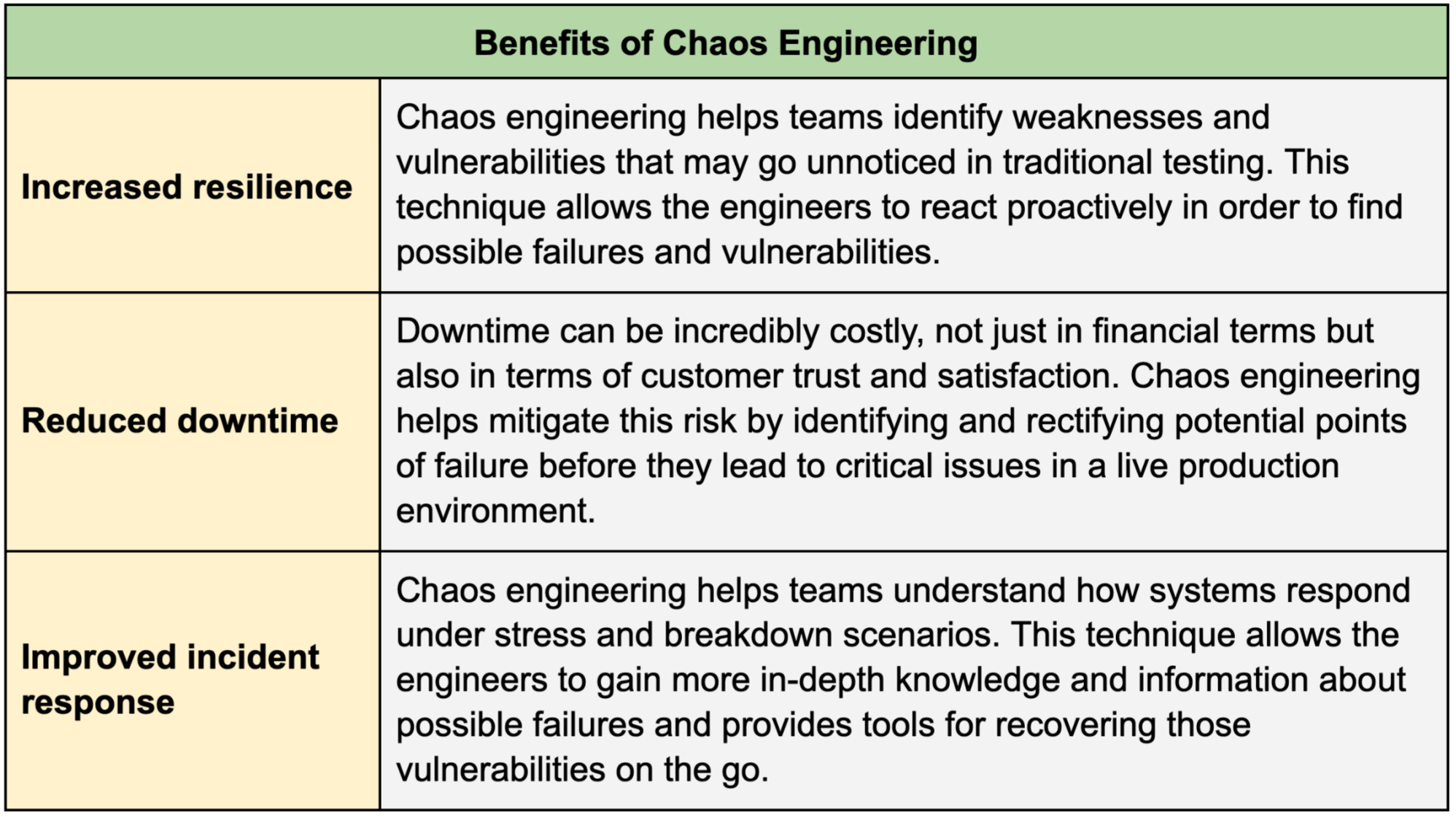
While chaos engineering offers significant benefits, it also presents some challenges. Let's explore some of the hurdles we might face when implementing chaos engineering practices.
Putting safety first: Safety should always come first when it comes to chaos engineering. Before jumping into testing, it's essential to back up all critical production data. Having a solid plan to reverse any changes or halt the testing if things take an unexpected turn is also vital. This safety net helps prevent any unintended consequences that could affect your services or customers.
Resource intensiveness: Chaos engineering requires a significant investment of time and resources. It's important to weigh the costs and benefits before diving in. Consider what the organization can realistically commit to in terms of time, human resources, and infrastructure. Focusing on experiments that offer the most value and align with the business objectives will help ensure that the efforts in chaos engineering are both effective and efficient.
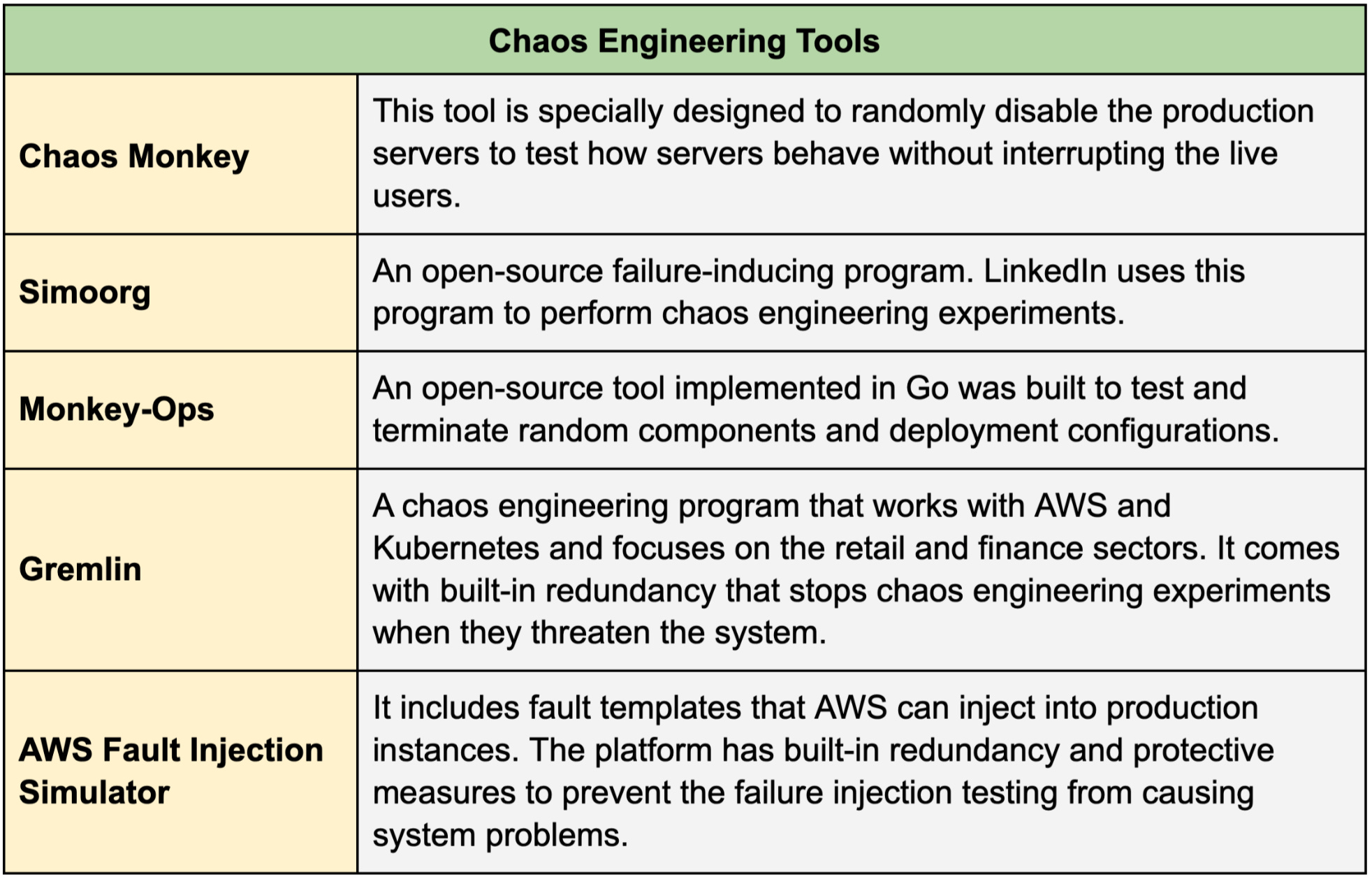
We list some of the most popular chaos engineering tools below.
We've explored the power of chaos engineering in enhancing system resilience and reliability in modern software development. We began by tracing the evolution of testing practices, from the traditional reluctance to test in production to the current embrace of chaos experimentation as a means of fortifying systems against failure. We then discussed the core concepts of chaos engineering and explained how it is different from performance engineering.
We also outlined key principles to guide effective chaos engineering practices and illustrated the real-world impact of chaos engineering from industry leaders like Netflix, Amazon, Microsoft Azure, and Spotify.
Chaos engineering offers a proactive and systematic approach to enhancing system resilience and reliability in today's complex and ever-changing technological landscape.
We hope that you have enjoyed reading this issue as much as we have in writing it.