Netflix began its life in 1997 as a mail-based DVD rental business.
Marc Randolph and Reed Hastings got the idea of Netflix while carpooling between their office and home in California.
Hastings admired Amazon and wanted to emulate their success by finding a large category of portable items to sell over the Internet. It was around the same time that DVDs were introduced in the United States and they tested the concept of selling or renting DVDs by mail.
Fast forward to 2024, Netflix has evolved into a video-streaming service with over 260 million users from all over the world. Its impact has been so humongous that “Netflix being down” is often considered an emergency.
To support this amazing growth story, Netflix had to scale its architecture on multiple dimensions.
In this article, we attempt to pull back the curtains on some of the most significant scaling challenges they faced and how those challenges were overcome.
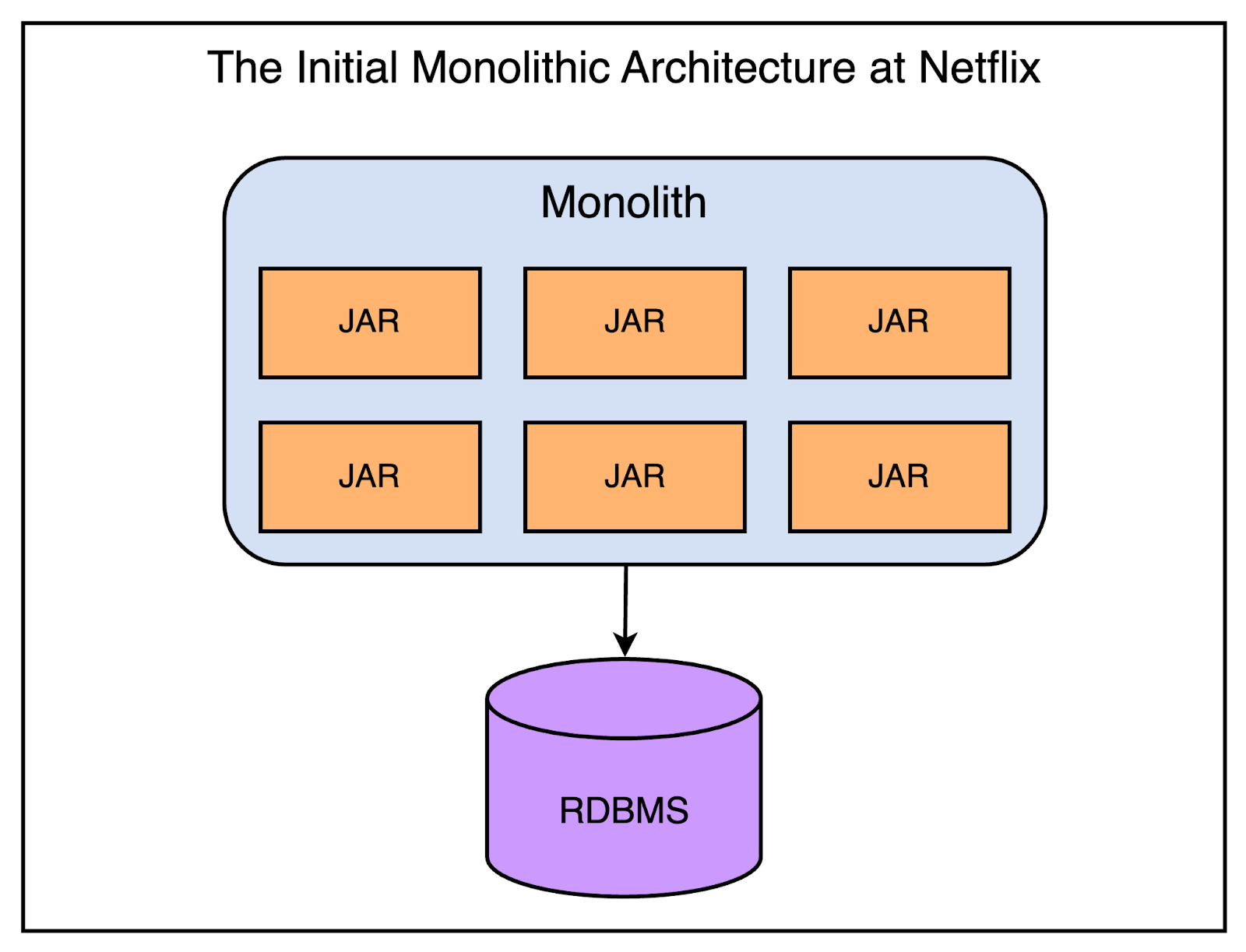
Like any startup looking to launch quickly in a competitive market, Netflix started as a monolithic application.
The below diagram shows what their architecture looked like a long time ago.
The application consisted of a single deployable unit with a monolithic database (Oracle). As you can notice, the database was a possible single point of failure.
This possibility turned into reality in August 2008.
There was a major database corruption issue due to which Netflix couldn’t ship any DVDs to the customers for 3 days. It suddenly became clear that they had to move away from a vertically scaled architecture prone to single points of failure.
As a response, they made two important decisions:
Move all the data to the AWS cloud platform
Evolve the systems into a microservices-based architecture
The move to AWS was a crucial decision.
When Netflix launched in 2007, EC2 was just getting started and they couldn’t leverage it at the time. Therefore, they built two data centers located right next to each other.
However, building a data center is a lot of work. You’ve to order equipment, wait for the equipment to arrive and install it. Before you finish, you’ve once again run out of capacity and need to go through the whole cycle again.
To cut through this cycle, Netflix went for a vertical scaling strategy that led to their early system architecture being modeled as a monolithic application.
However, the outage we talked about earlier taught Netflix one critical lesson - building data centers wasn’t their core capability.
Their core capability was delivering video to the subscribers and it would be far better for them to get better at delivering video. This prompted the move to AWS with a design approach that can eliminate single points of failure.
It was a mammoth decision for the time and Netflix adopted some basic principles to guide them through this change:
First, try to use or contribute to open-source technology wherever possible.
Only build from scratch what you absolutely must.
Services should be built in a stateless manner except for the persistence or caching layers.
No sticky sessions.
Employ chaos testing to prove that an instance going down doesn’t impact the wider system.
Horizontal scaling gives you a longer runway in terms of scalability.
Prefer to go for horizontal scaling instead of vertical scaling.
Make more than one copy of anything. For example, replica databases and multiple service instances.
Reduce the blast radius of any issue by isolating workloads.
Destructive testing of the systems should be an ongoing activity.
Adoption of tools like Chaos Monkey to carry out such tests at scale.
These guiding principles acted as the North Star for every transformational project Netflix took up to build an architecture that could scale according to the demands.
The overall Netflix architecture is divided into three parts:
The Client
The Backend
The Content Delivery Network

The client is the Netflix app on your mobile, a website on your computer or even the app on your Smart TV. It includes any device where the users can browse and stream Netflix videos. Netflix controls each client for every device.
The backend is the part of the application that controls everything that happens before a user hits play. It consists of multiple services running on AWS and takes care of various functionalities such as user registration, preparing incoming videos, billing, and so on. The backend exposes multiple APIs that are utilized by the client to provide a seamless user experience.
The third part is the Content Delivery Network also known as Open Connect. It stores Netflix videos in different locations throughout the world. When a user plays a video, it streams from Open Connect and is displayed on the client.
The important point to note is that Netflix controls all three areas, thereby achieving complete vertical integration over their stack.
Some of the key areas that Netflix had to scale if they wanted to succeed were as follows:
The Content Delivery Network
The Netflix Edge
APIs
Backend Services with Caching
Authorization
Memberships
Let’s look at each of these areas in more detail.
Imagine you’re watching a video in Singapore and the video is being streamed from Portland. It’s a huge geographic distance broken up into many network hops. There are bound to be latency issues in this setup resulting in a poorer user experience.
If the video content is moved closer to the people watching it, the viewing experience will be a lot better.
This is the basic idea behind the use of CDN at Netflix.
Put the video as close as possible to the users by storing copies throughout the world. When a user wants to watch a video, stream it from the nearest node.
Each location that stores video content is called a PoP or point of presence. It’s a physical location that provides access to the internet and consists of servers, routers and other networking equipment.
However, it took multiple iterations for Netflix to scale their CDN to the right level.
Netflix debuted its streaming service in 2007.
At the time, it had over 35 million members across 50 countries, streaming more than a billion hours of video each month
To support this usage, Netflix built its own CDN in five different locations within the United States. Each location contained all of the content.
In 2009, Netflix started to use 3rd party CDNs.
The reason was that 3rd-party CDN costs were coming down and it didn’t make sense for Netflix to invest a lot of time and effort in building their own CDN. As we saw, they struggled a lot with running their own data centers.
Moving to a 3rd-party solution also gave them time to work on other higher-priority projects. However, Netflix did spend a lot of time and effort in developing smarter client applications to adapt to changing network conditions.
For example, they developed techniques to switch the streaming to a different CDN to get a better result. Such innovations allowed them to provide their users with the highest quality experience even in the face of errors and overloaded networks.
Sometime around 2011, Netflix realized that they were operating at a scale where a dedicated CDN was important to maximize network efficiency and viewing experience.
The streaming business was now the dominant source of revenue and video distribution was a core competency for Netflix. If they could do it with extremely high quality, it could turn into a huge competitive advantage.
Therefore, in 2012, Netflix launched its own CDN known as Open Connect.
To get the best performance, they developed their own computer system for video storage called Open Connect Appliances or OCAs.
The below picture shows an OCA installation:

An OCA installation was a cluster of multiple OCA servers. Each OCA is a fast server that is highly optimized for delivering large files. They were packed with lots of hard disks or flash drives for storing videos.
Check the below picture of a single OCA server:

The launch of Open Connect CDN had a lot of advantages for Netflix:
It was more scalable when it came to providing service everywhere in the world.
It had better quality because they could now control the entire video path from transcoding, CDN, and clients on the devices.
It was also less expensive as compared to 3rd-party CDNs.
The next critical piece in the scaling puzzle of Netflix was the edge.
The edge is the part of a system that’s close to the client. For example, out of DNS and database, DNS is closer to the client and can be thought of as edgier. Think of it as a degree rather than a fixed value.
Edge is the place where data from various requests enters into the service domain. Since this is the place where the volume of requests is highest, it is critical to scale the edge.
The Netflix Edge went through multiple stages in terms of scaling.
The below diagram shows how the Netflix architecture looked in the initial days.
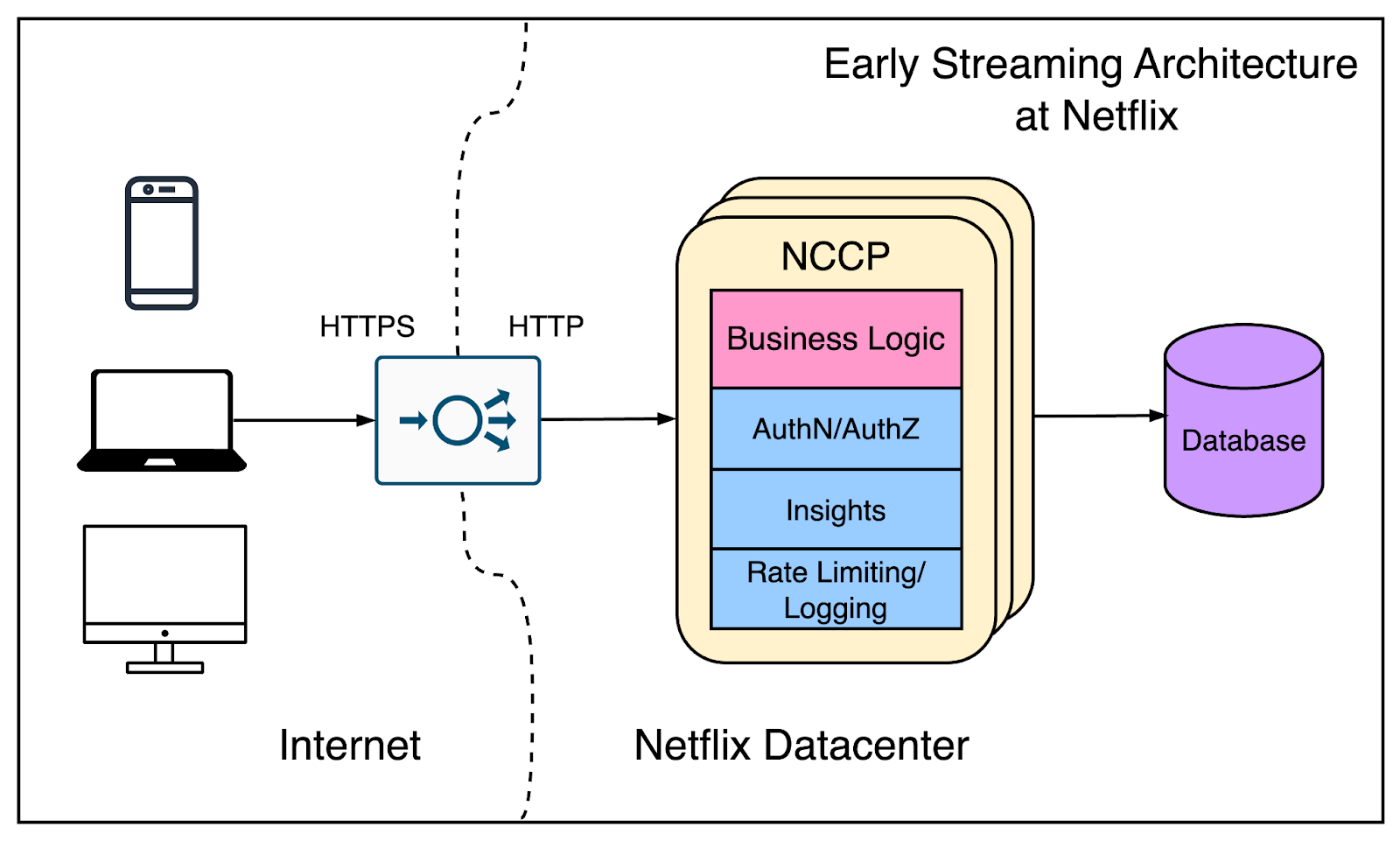
As you can see, it was a typical three-tier architecture.
There is a client, an API, and a database that the API talks to. The API application was named NCCP (Netflix Content Control Protocol) and it was the only application that was exposed to the client. All the concerns were put into this application.
The load balancer terminated the TLS and sent plain traffic to the application. Also, the DNS configuration was quite simple. The idea was that clients should be able to find and reach the Netflix servers.
Such a design was dictated by the business needs of the time. They had money but not a lot. It was important to not overcomplicate things and optimize for time to market.
As the customer base grew, more features were added. With more features, the company started to earn more money.
At this point, it was important for them to maintain the engineering velocity. This meant breaking apart the monolithic application into microservices. Features were taken out of the NCCP application and developed as separate apps with separate data.
However, the logic to orchestrate between the services was still within the API. An incoming request from a client hits the API and the API calls the underlying microservices in the right order.
The below diagram shows this arrangement:
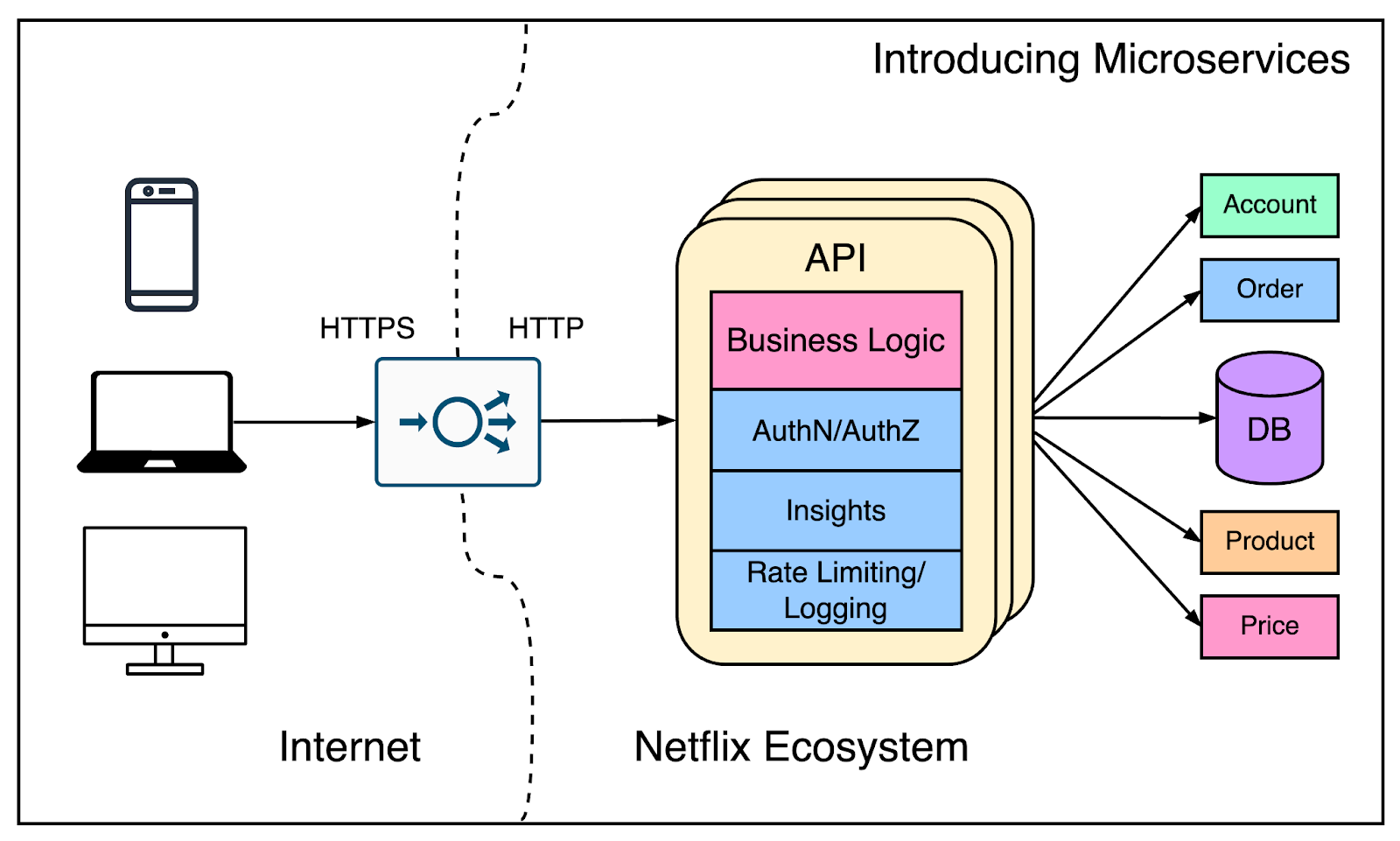
Over time the API application got bigger and bigger turning into a monolith. It was important to split it but unlike other services, the API was an Edge service and a contract to the client. There was some sort of orchestration needed on the client side.
Two approaches were followed:
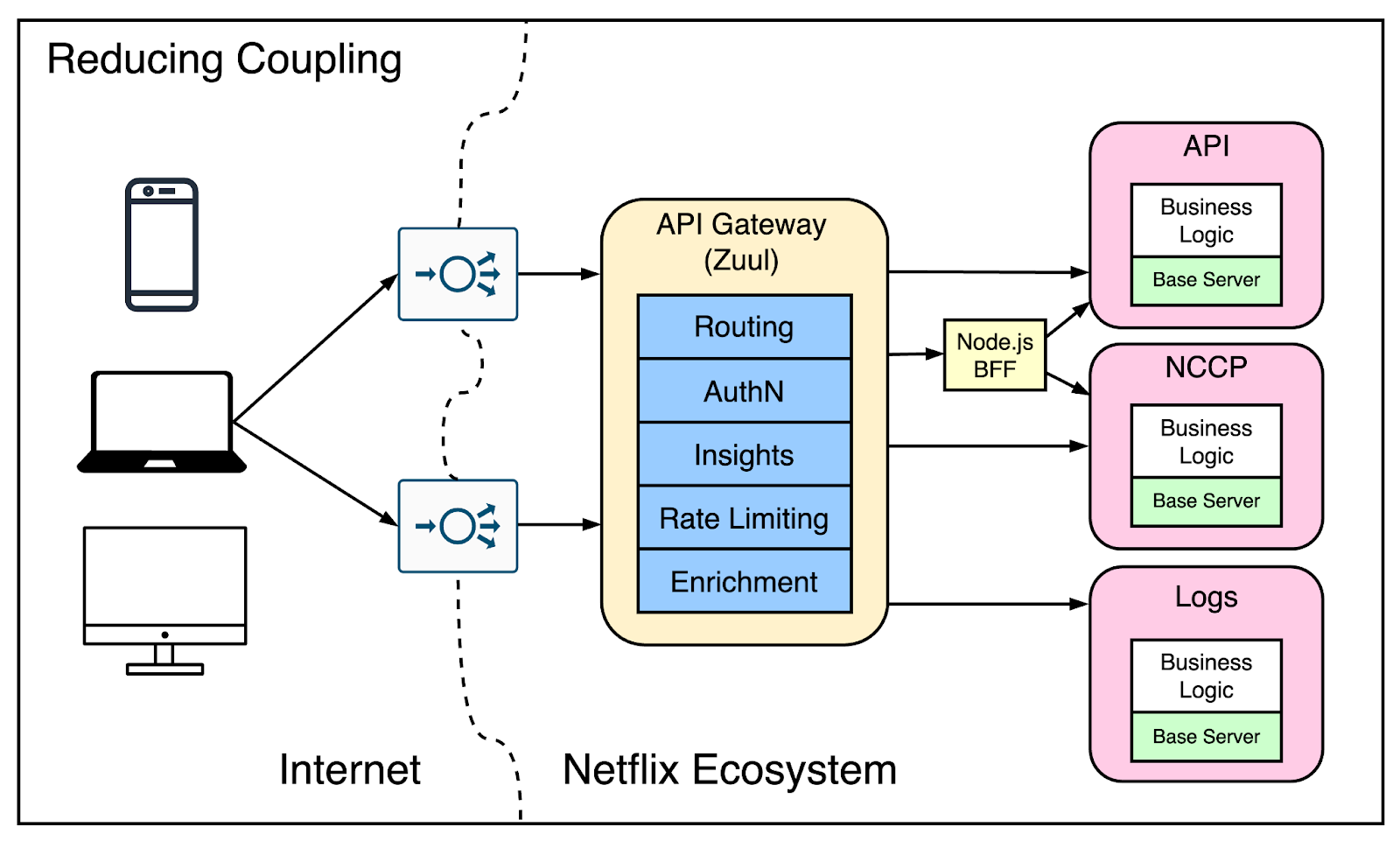
Initially, Netflix split the application using client-side orchestration. The NCCP was split into two. The NCCP stayed there for the playback experience while other APIs started to handle the discovery experiences. There were multiple domain names supported by multiple load balancers.
Next, an API Gateway was introduced since there was a need to split a lot of functionality on the Edge. This helped a lot as more services such as backend-for-frontends were added. The API Gateway helped reduce the coupling between the client and the services.
For reference, the API Gateway was called Zuul. It’s an open-source technology developed by Netflix as part of its open-source initiative. Zuul helped Netflix handle several concerns such as authentication, routing, and other customer-related routing decisions.
See the below diagram that shows how Zuul was integrated into the overall setup:
In 2013 and 2014, Netflix spent a lot of effort to support multi-region deployment.
This was a critical requirement for scalability and high availability of the system at a global level. If one region goes down, they can simply route the client to a different region.
To support this feature, they built a DNS-based steering system.
Here’s what it looked like on a high level:
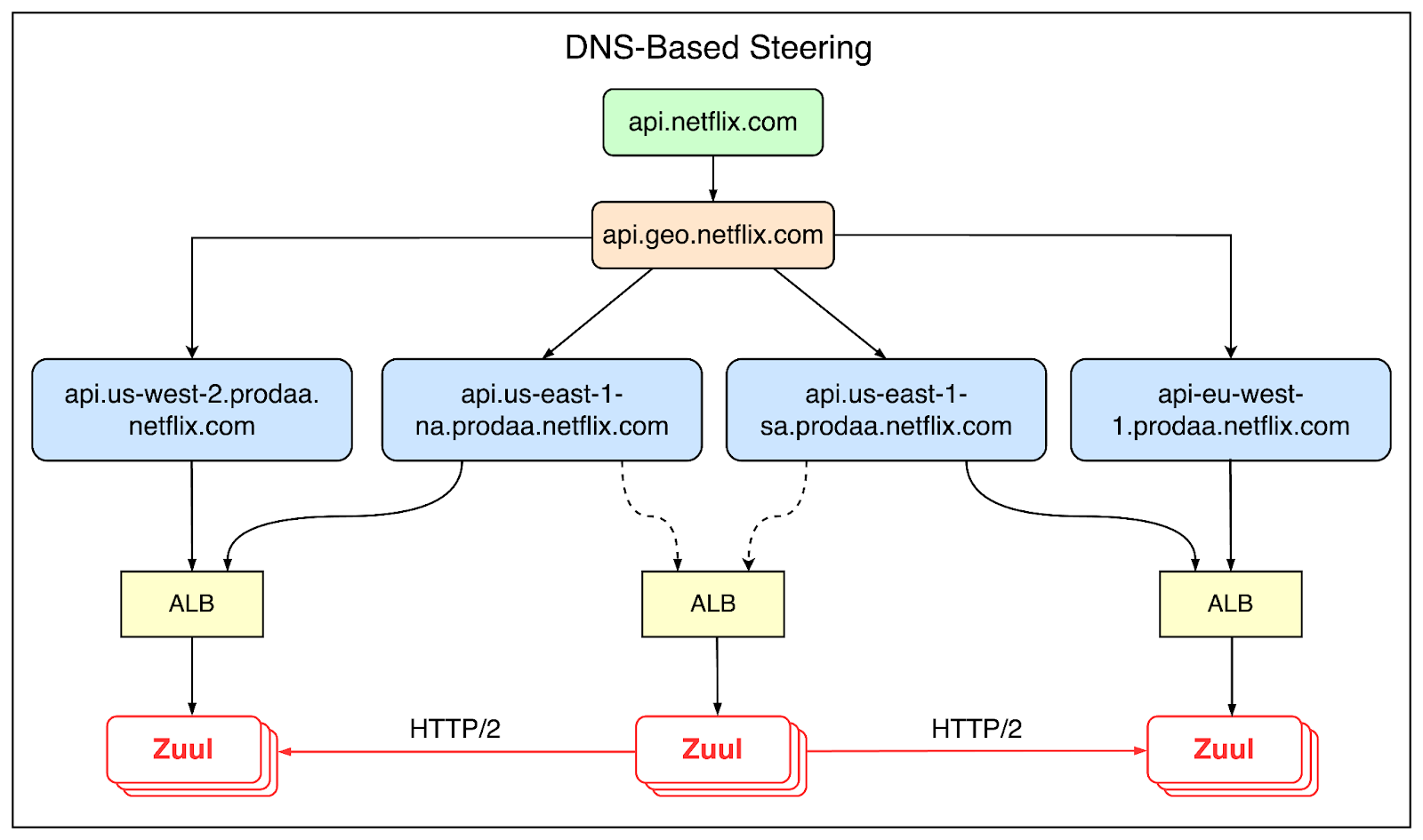
While building microservices, Netflix had an important goal to make them loosely coupled and highly scalable. Independent services allow for evolution at different paces and independent scaling. However, they also add complexity to data requirements that span multiple services.
To handle this, Netflix built a unified API aggregation layer at the edge.
This was good for both UI and backend developers. UI developers enjoyed the simplicity of working with one conceptual API for a large domain. On the other hand, backend developers loved the decoupling offered by the API layer.
However, as the business scaled and the domain complexity increased, developing the API aggregation layer became harder.
To address this, Netflix developed a federated GraphQL platform to power the API layer.
The below diagram shows the high-level design of this setup.
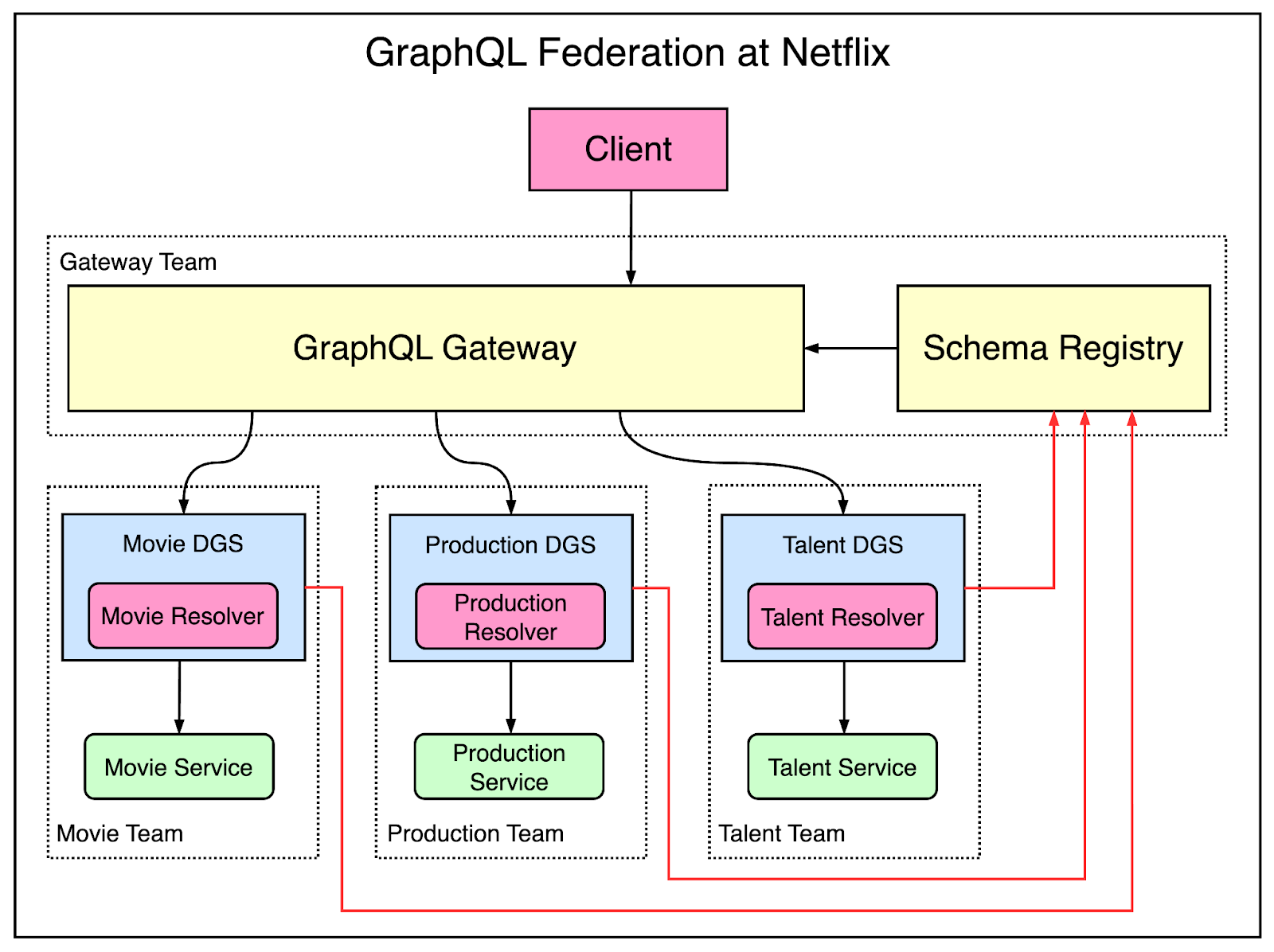
The example shows the application of GraphQL Federation on the Studio API of Netflix. It was the first part of the Netflix ecosystem where they tried GraphQL Federation.
There are three main components of this setup:
Domain Graph Service (DGS) for each domain item (such as movie, production or talent). Developers define their own federated GraphQL schema in a DGS. A DGS is owned and operated by a domain team.
Schema Registry is a stateful component that stores all the schemas and schema changes for every DGS.
GraphQL Gateway is responsible for serving GraphQL queries to the consumers. It takes a query from a client, breaks it into smaller sub-queries and executes the plan by proxying calls to the appropriate downstream DGSs.
There were a couple of key advantages of this setup:
The GraphQL schema was unified for the Studio API product. This provided a coherent view of the functionalities for the developers.
The implementation of the resolvers was decentralized to the respective domain teams. This allowed for ownership of the entire service to stay with the domain team resulting in faster iterations.
In a nutshell, the goal of GraphQL Federation was to provide a unified API for the consumers while also giving a lot of flexibility to the backend teams to iterate on their services.
Netflix wants you to chill and keep streaming for as long as possible. However, the average amount of time they have to grab your attention is just 90 seconds.
Bottlenecks like a slow internet connection or hanging requests to a database can quickly eat into those 90 seconds. This is where they use EVCache to reduce latency and improve the application performance.
EVCache is a distributed key-value store optimized for use on AWS and tuned specifically for the requirements of Netflix.
Below is the high-level architecture behind EVCache.
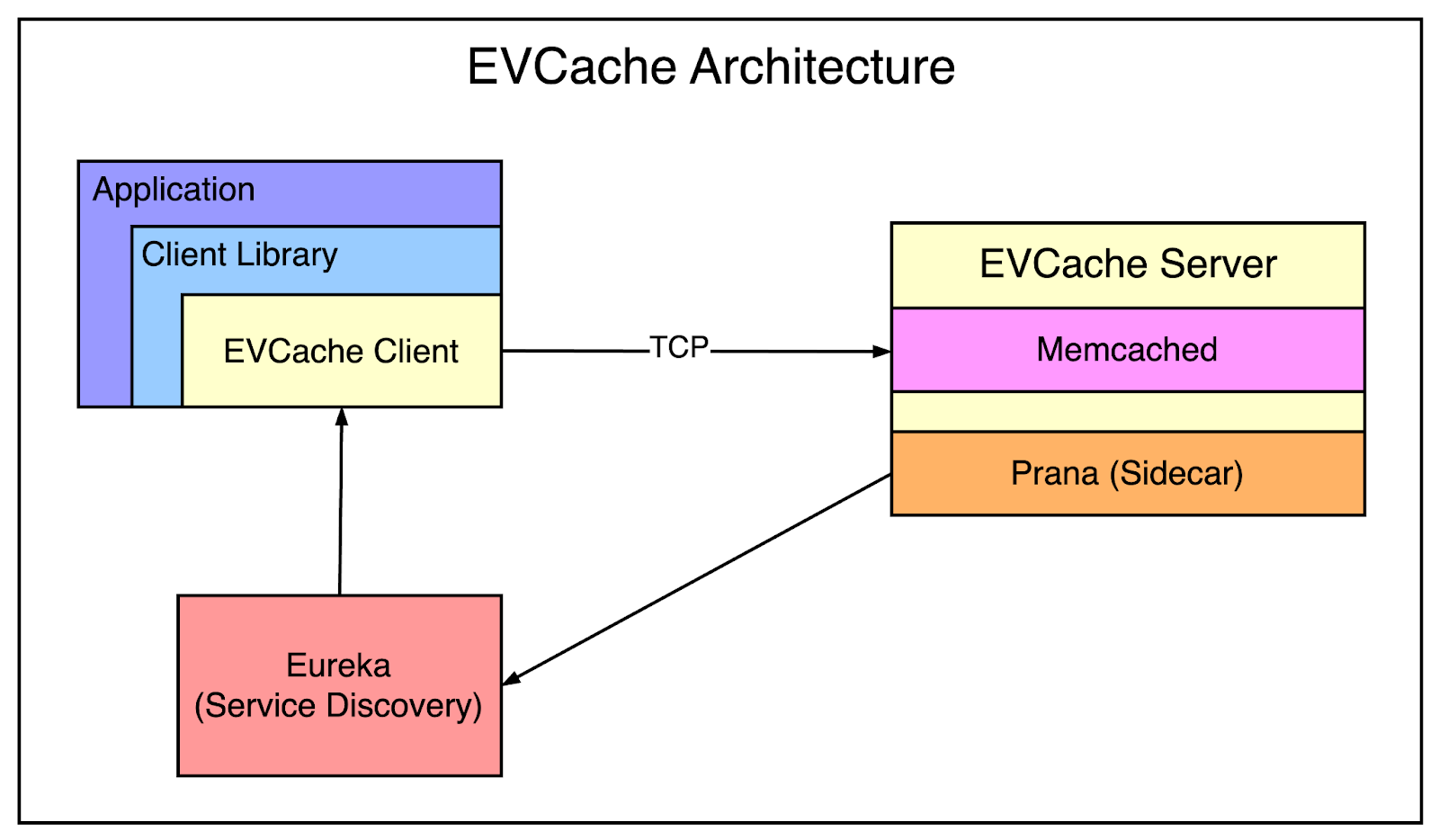
On the client side, the EVCache client is accessed via the client library of an online application. The client library directly talks to the cache via a TCP connection.
The EVCache Server is based on memcached. It also has a sidecar process known as Prana that allows non-Java services to use EvCache. Prana also lets EVCache hook into the Netflix infrastructure to report on metrics and connect to service discovery.
To support scalability, EVCache is built to maintain 3 whole copies of data across different AWS availability zones. All clients are connected to all servers in a cluster across availability zones and regions. See the below diagram that shows this arrangement.
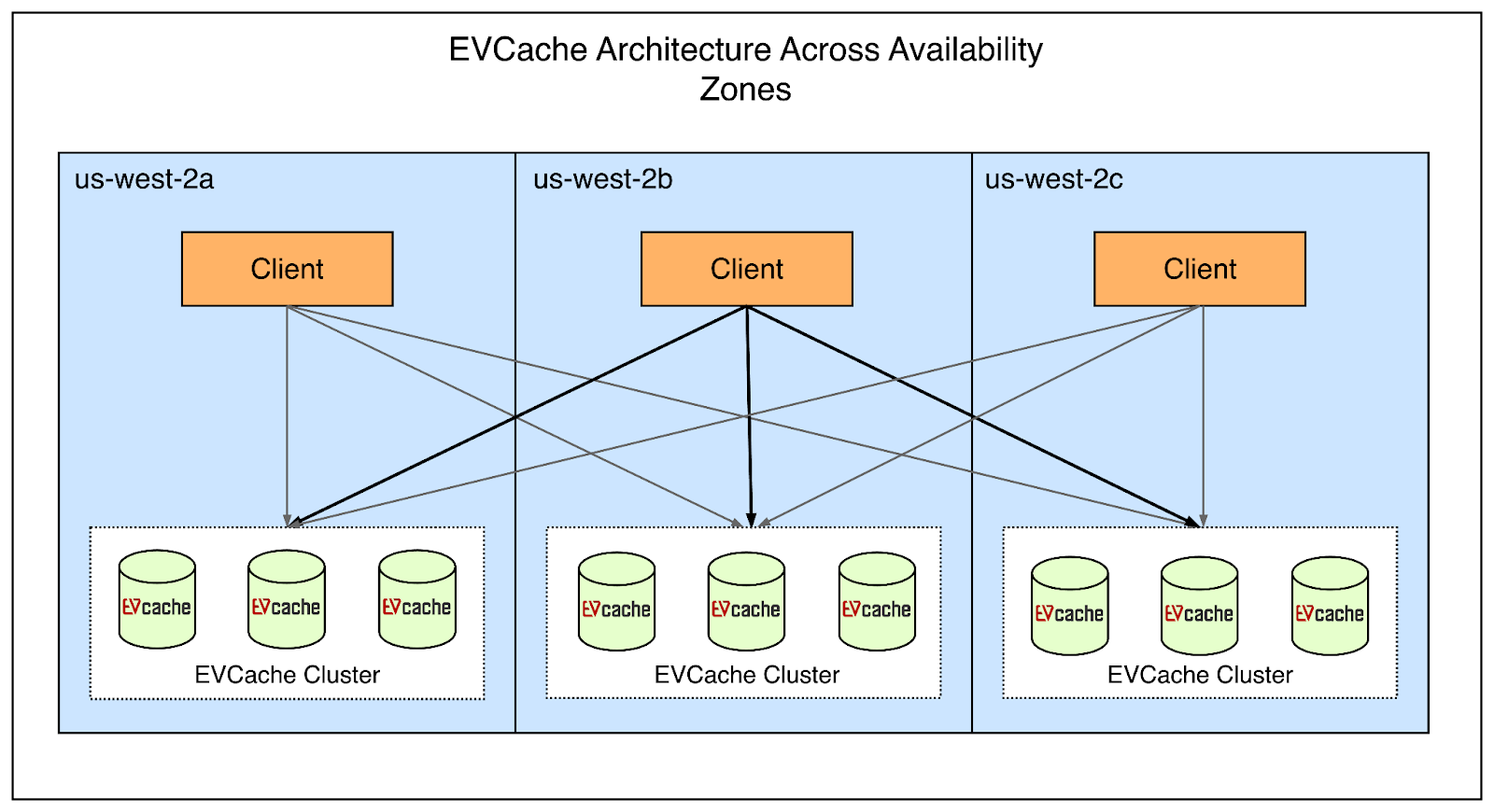
When reading from the cache, a client attempts to read from the primary or closest cluster. If the read fails, it will try secondaries in other regions. For writes, a client will write to all three zones to enforce data replication across regions.
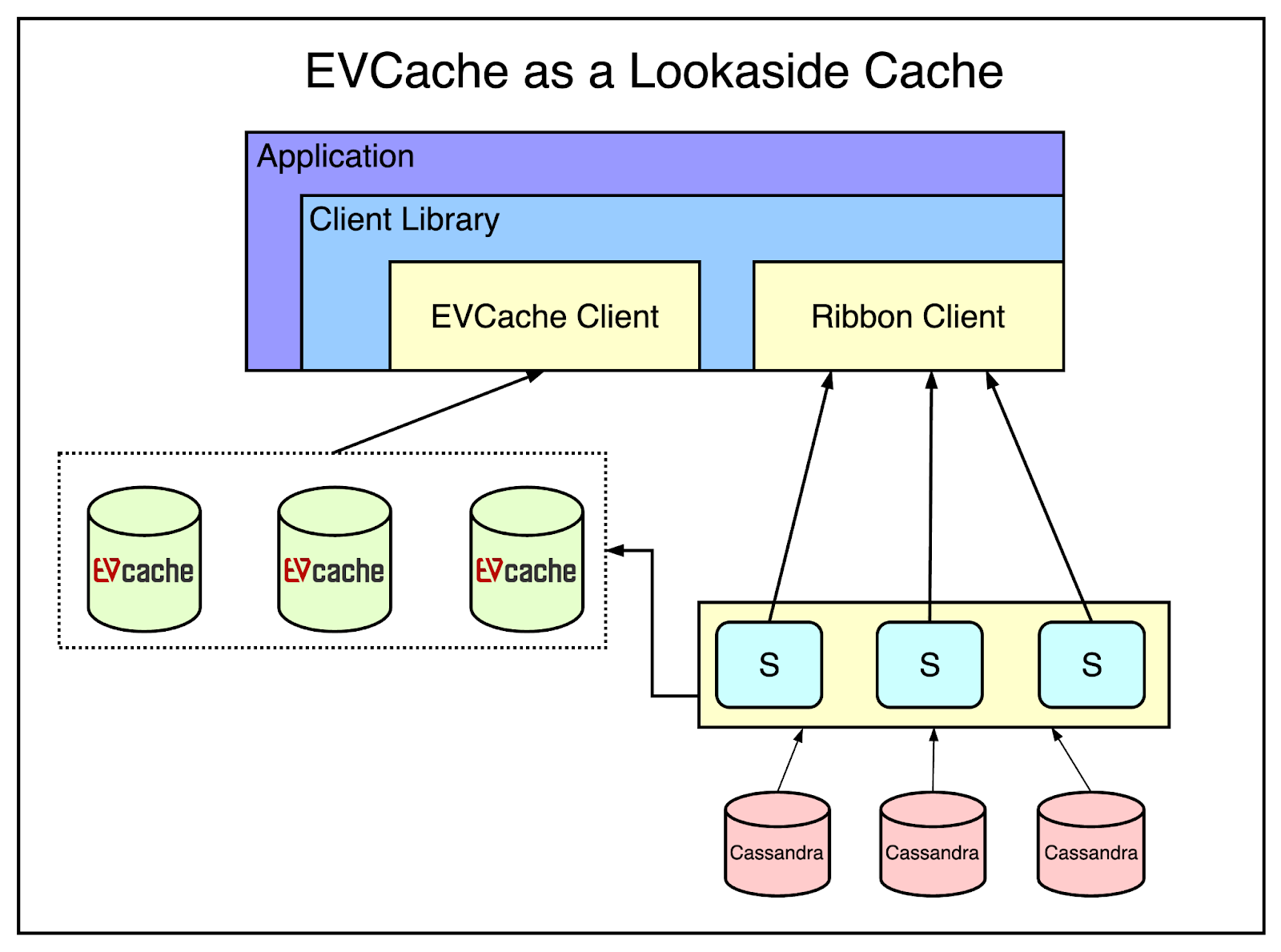
There are 4 main use cases where Netflix uses EVCache:
When the application requests some data, it first tries the EVCache client and if the data is not there, they go to the backend service and the Cassandra database to fetch the data.
The service is also responsible for updating the EVCache.
The below diagram shows this setup.
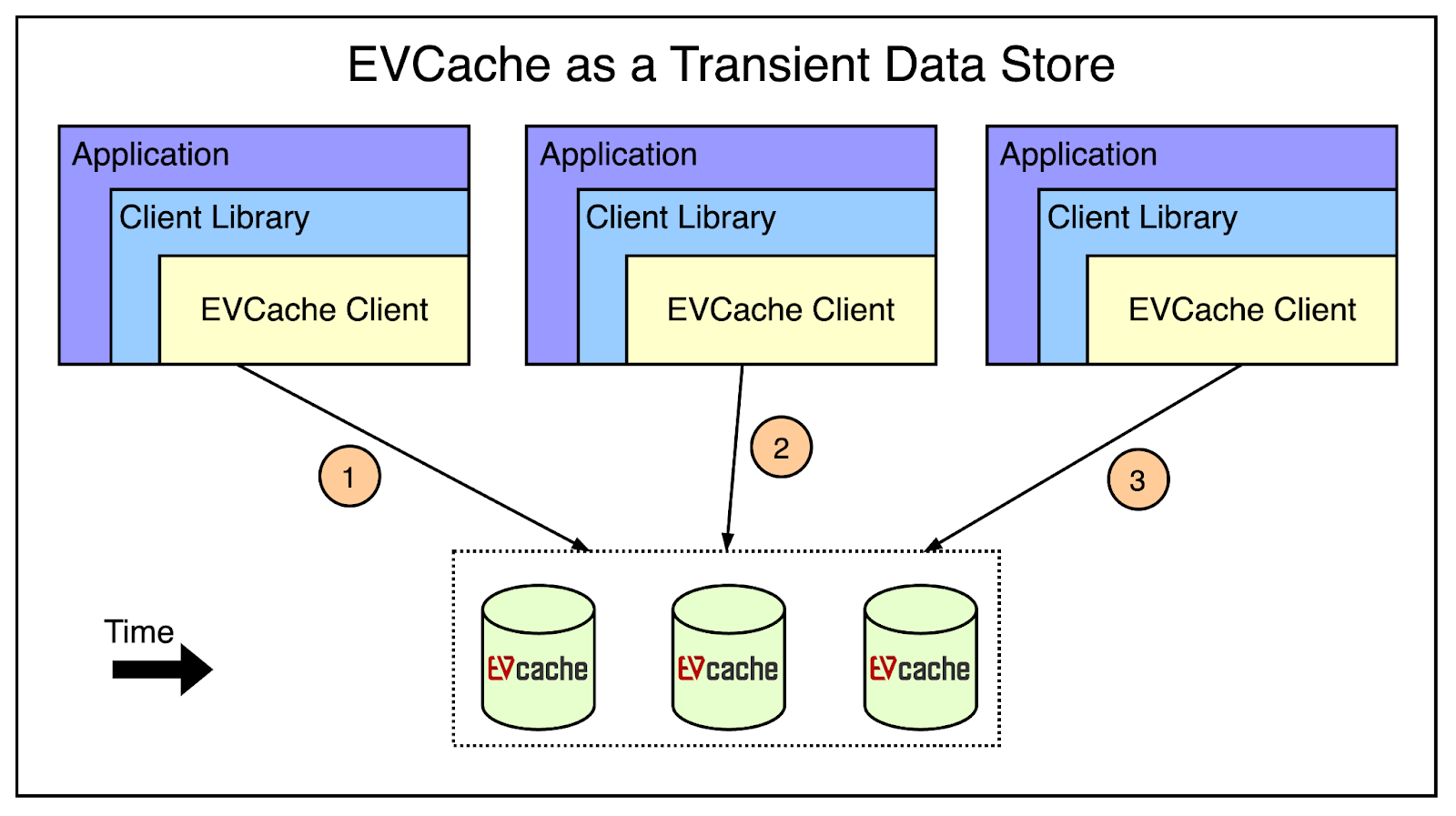
The second application is storing transient data in EVCache such as keeping track of playback session information.
One application service might start the session while the other may update the session followed by a session closure at the very end.
The below diagram shows this use case:
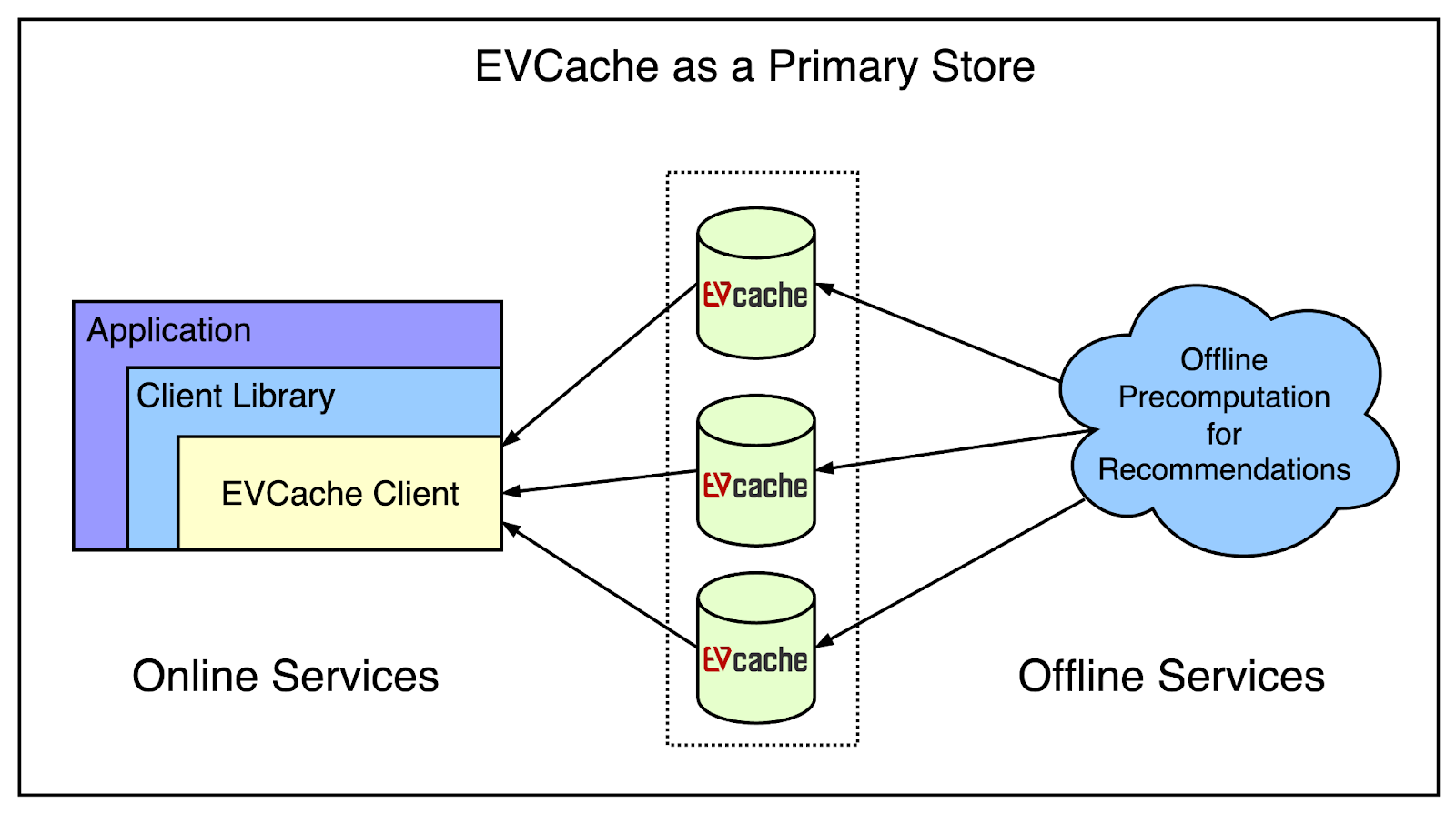
This is the largest usage footprint of EVCache at Netflix.
They have large-scale pre-compute systems that run every night to compute a brand-new home page for every profile of every user. All of that data is written into the EVCache cluster.
The online services can read all of this data without worrying about when the data was written. The cache acts as a buffer between the offline and online applications.
The below diagram shows the use of EVCache as a primary store.
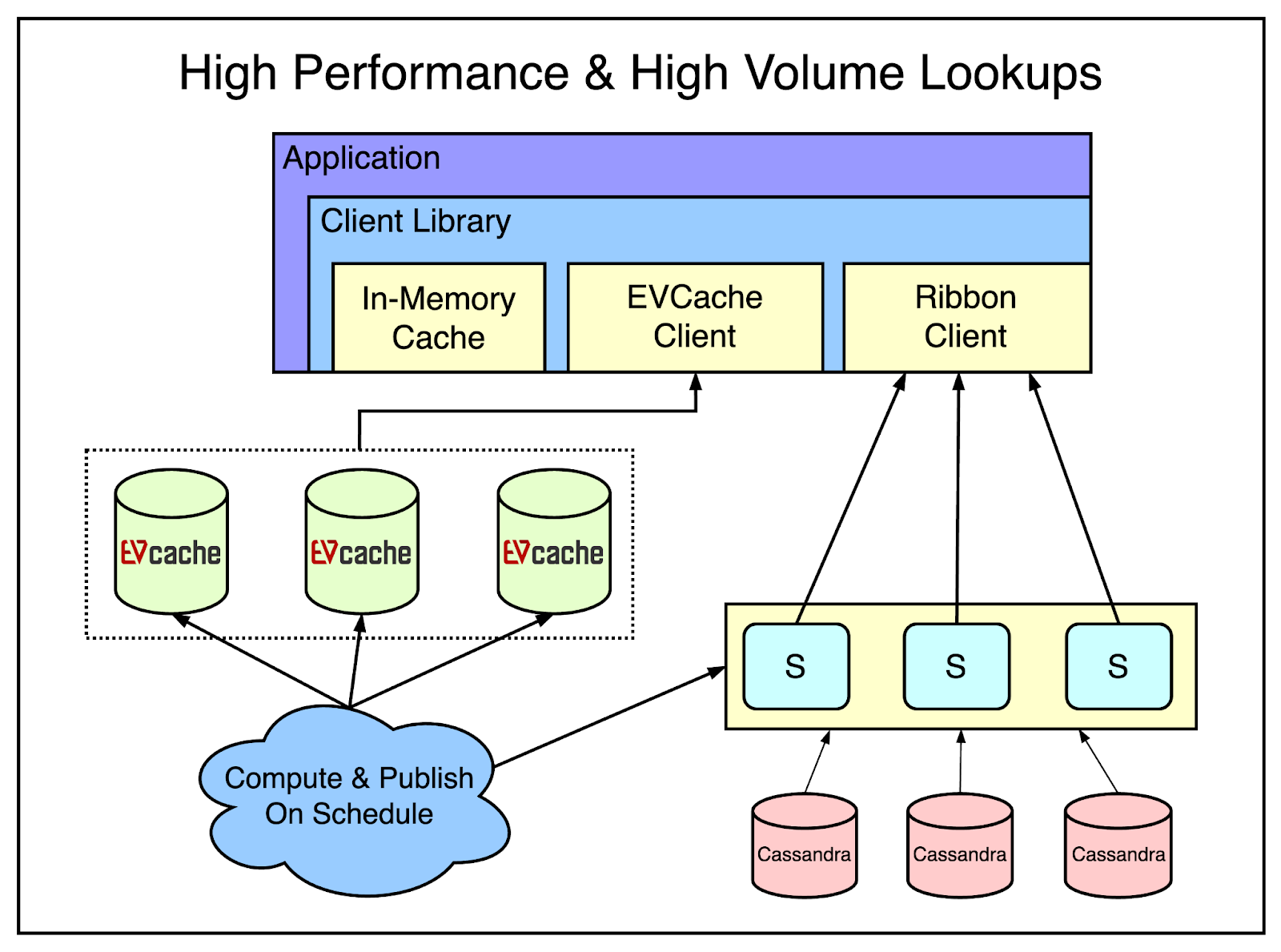
Netflix also has some data that is high volume and also needs to be highly available.
For example, UI strings that are shown on the Netflix home page. Missing UI strings can result in a very poor user experience.
To deal with such data, applications use an in-memory cache. However, if the in-memory cache doesn’t have the data, the application can reach out to EVCache. Also, the application can perform a background refresh of this data from the source-of-truth database.
A different process is asynchronously computing and publishing the updated UI strings to EVCache.
For any application, authorization is a critical functionality. However, at the scale of Netflix, the problem becomes a major engineering challenge.
Some of the challenges in this space were as follows:
How to authorize 3M requests per second?
How to bring in complex signals (such as fraud and device-sharing rules) into the authorization flow?
How to evolve the design to changing needs?
In 2018, the authorization for the Netflix streaming product looked something like this:
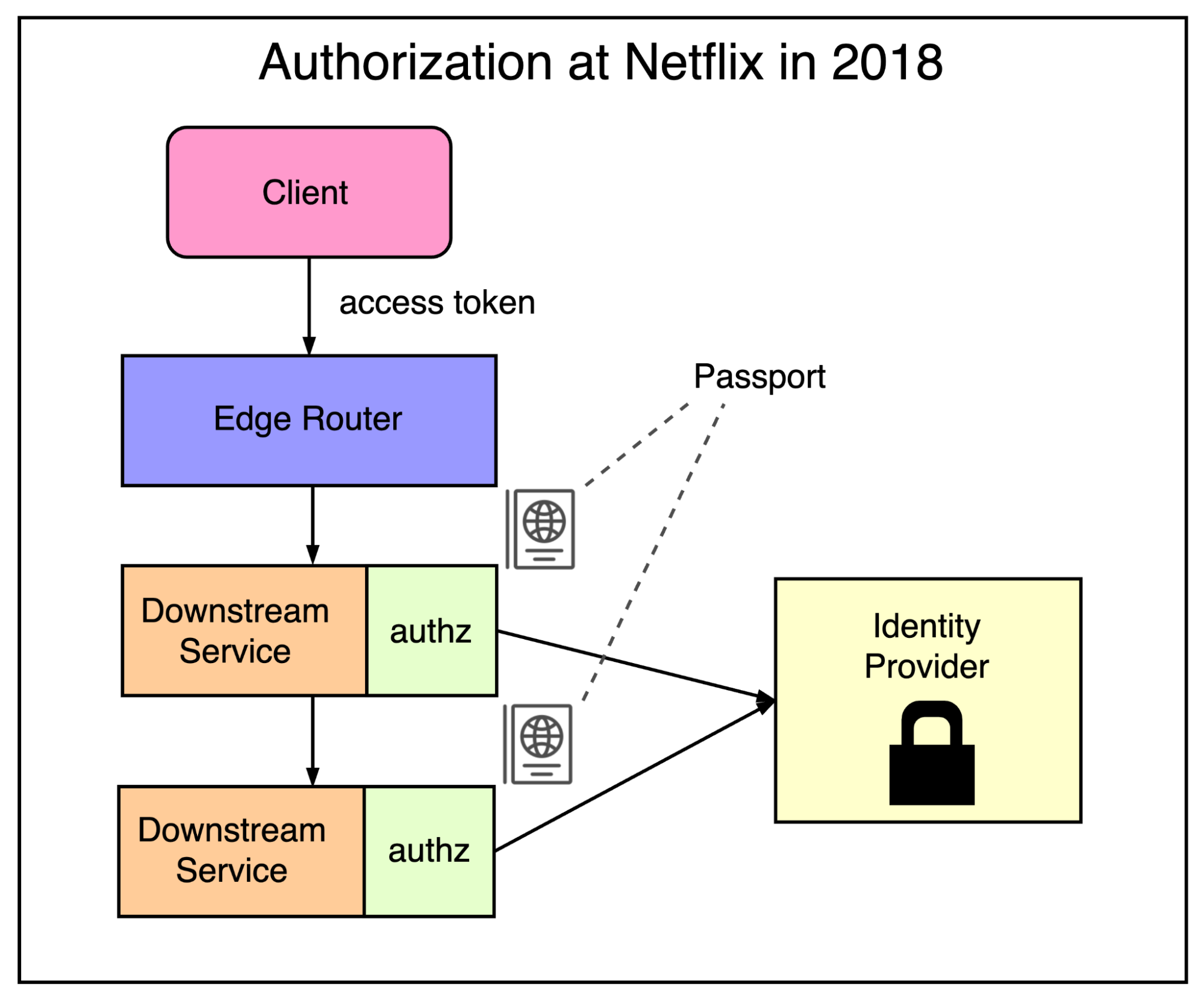
The client would pass an access token to the edge router.
The edge router would transform that into a passport that was an internal token-agnostic identity for the user. It contained all the relevant user and device information.
The passport would be passed along to any number of downstream microservices.
Each of these microservices will have its own authorization rules based on the identity. These services may also call out to our identity provider to check the current status of that user.
As you can see, the trouble with this design was that the authorization rules were getting replicated across multiple microservices. This was like replicating a piece of code hundreds of times.
Though this approach was scalable, it wasn’t flexible. Making changes was difficult as multiple services had to be modified. Also, the policies about authorization were quite simple.
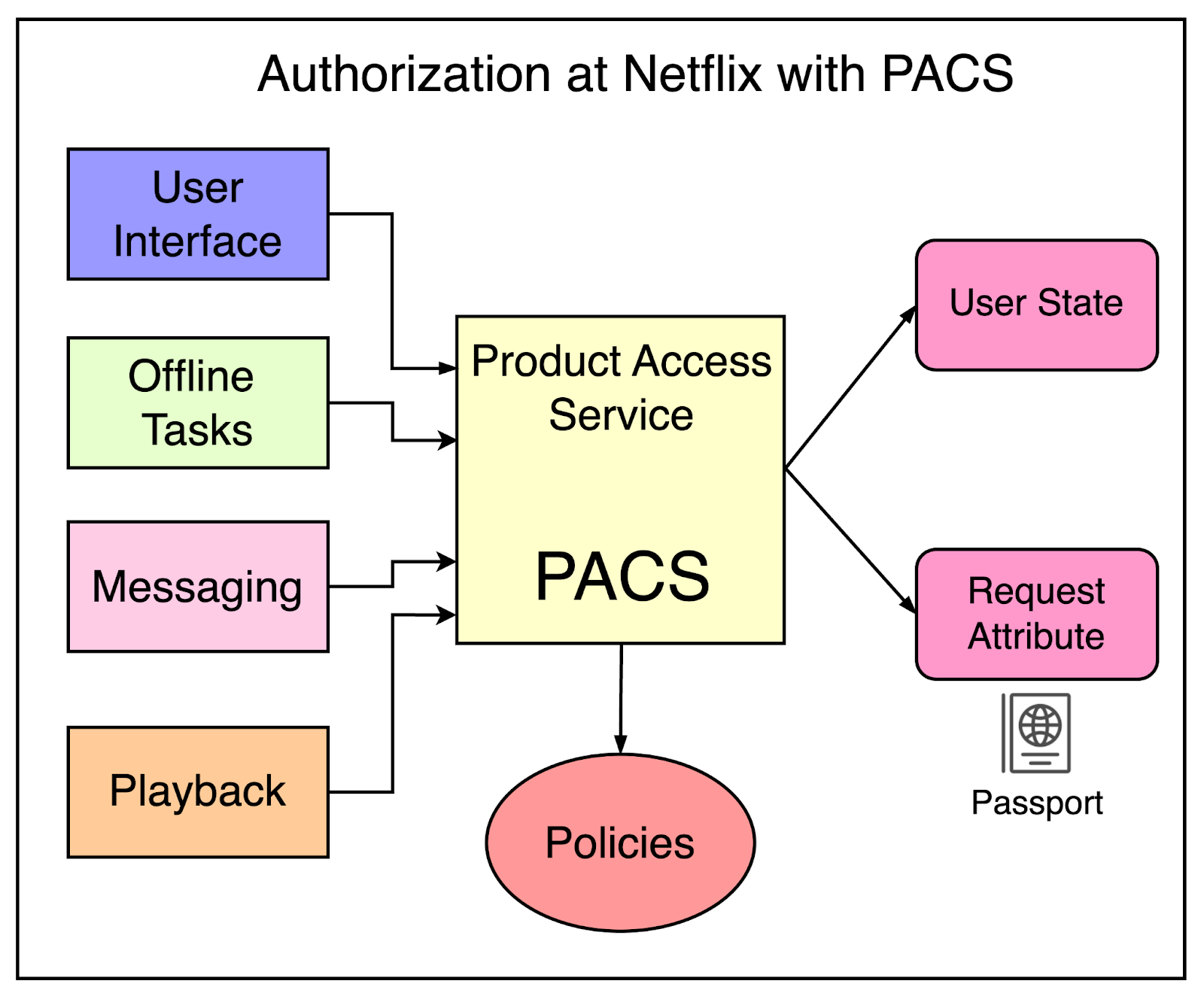
To address these challenges, Netflix built a central authorization service known as PACS (Product Access Service). This service had different types of clients such as UIs, Offline Tasks, Messaging, and Playback services.
PACS also has access to policies that help define various levels of access. Also, PACS can get the user state from the identity provider and access the request attributes along with the passport information for a user.
See the below diagram that shows PACS as the central authorization service:
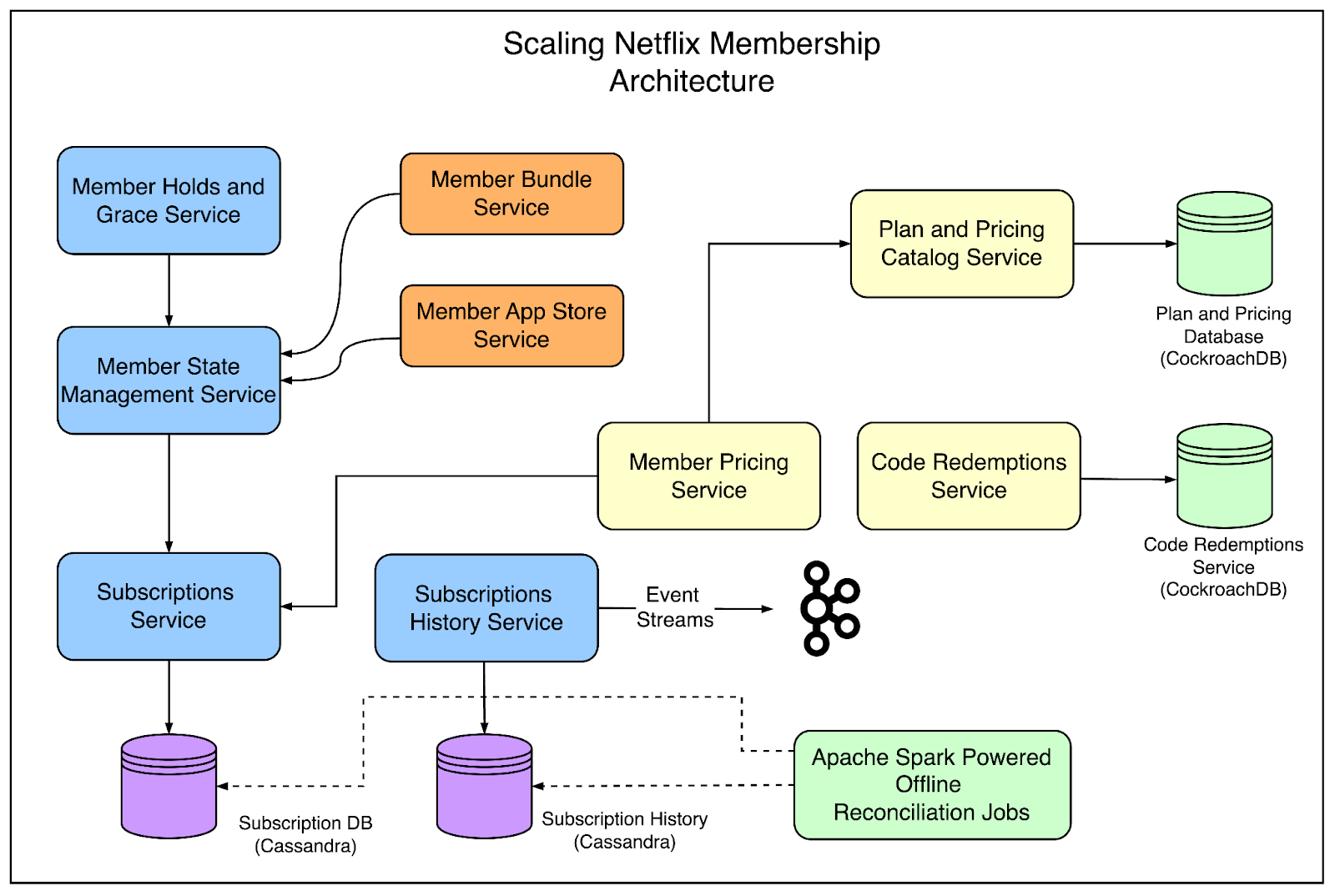
One of the most critical paths for signups as well as streaming at Netflix involves dealing with membership data. With 260 million subscribers, the scale and availability requirements are extremely important for the membership system.
Overall, the membership system operates a dozen microservices at a 99.99% availability guarantee.
The system owns mid-tier services that need to serve millions of requests per second. It also acts as the source of truth for analytics information such as total membership count and so on.
Some of the primary responsibilities of this system are as follows:
Manage the plan, price, billing country and payment status for all subscriptions
Maintain a catalog of all plans and prices across 190 countries
Manage the membership lifecycle of every subscriber from onboarding to billing.
See the below architecture that supports the membership system:
The architecture of Netflix has gone through multiple steps of evolution over the years.
In the initial days, Netflix started with a monolithic application. The move to a microservices architecture was prompted by the disastrous downtime they faced within their own data center. However, to make the transition, they laid out some key principles to design microservices.
As the overall scale of Netflix grew, they had to scale various parts of the system such as the Content Delivery, the Edge Layer, APIs, Backend Services, Authorization, and Membership.
In this article, we’ve tried to capture the scaling journey of various parts while taking away important learnings in the process.
References: