
The digital landscape has seen dramatic changes in how information is retrieved, moving from simple web portals to complex recommendation systems. This shift has been driven by the rapid increase of online content and the growing demand for personalized, relevant experiences. Let’s dive into the four pivotal stages for this evolution.
In the mid-1990s, search engines like Yahoo! were rudimentary, focusing on text-based searches with basic algorithms for indexing web pages. The search results were ranked based on keyword matches without considering the user’s context or personal preferences. This phase was about cataloging the burgeoning web content as the internet started its exponential growth.
Enter Google with its PageRank algorithm, revolutionizing search by evaluating not just keyword relevance but also the quality and quantity of page links. This significantly improved the relevance and quality of search results, marking a leap forward in information retrieval.
As the internet grew, search engines started to incorporate more nuanced data, including users’ search histories, locations, and devices, to refine search results. This period also introduced diverse content types – images, videos, and news – directly into search results, making the experience more personal and comprehensive. However, this increased personalization also sparked privacy and data protection concerns.
Today, we’re in an era dominated by AI and machine learning, powering recommendation systems that suggest content not based on explicit queries but on users’ past behaviors, preferences, and interactions. Giants like YouTube, Netflix, and Amazon rely on these systems to enhance engagement and drive sales.
Recommendation systems represent a significant shift from user-initiated information retrieval to active content curation. In the past, there wasn’t so much content online, and users could easily discover content through keyword-based searches. Now, with the internet’s vast expanses of data, platforms compete for users’ attention, and recommendation systems play a crucial role in filtering and presenting personalized content. It’s often quipped that these systems know us better than we know ourselves.
In this issue, we’ll explore the inner workings of recommendation systems and their pivotal role in driving a company’s revenue. Stay tuned as we uncover the secrets behind how YouTube and other platforms tailor content to captivate and engage their audiences.
Recommendation systems are everywhere these days. Whether shopping on Amazon, binge-watching on YouTube or scrolling through TikTok, these systems curate content specifically for us, potentially leading to hours of engagement. But why are these systems so crucial, especially for platforms like YouTube?
At the heart of platforms like YouTube is a dynamic ecosystem involving content creators, viewers, and advertisers. Content creators produce videos, viewers consume this content, and advertisers aim to capture viewers’ attention. Recommendation systems play a pivotal role in enhancing this ecosystem, attracting more creators, viewers, and advertisers.
The diagram below shows the effects of a recommendation system on the YouTube platform.
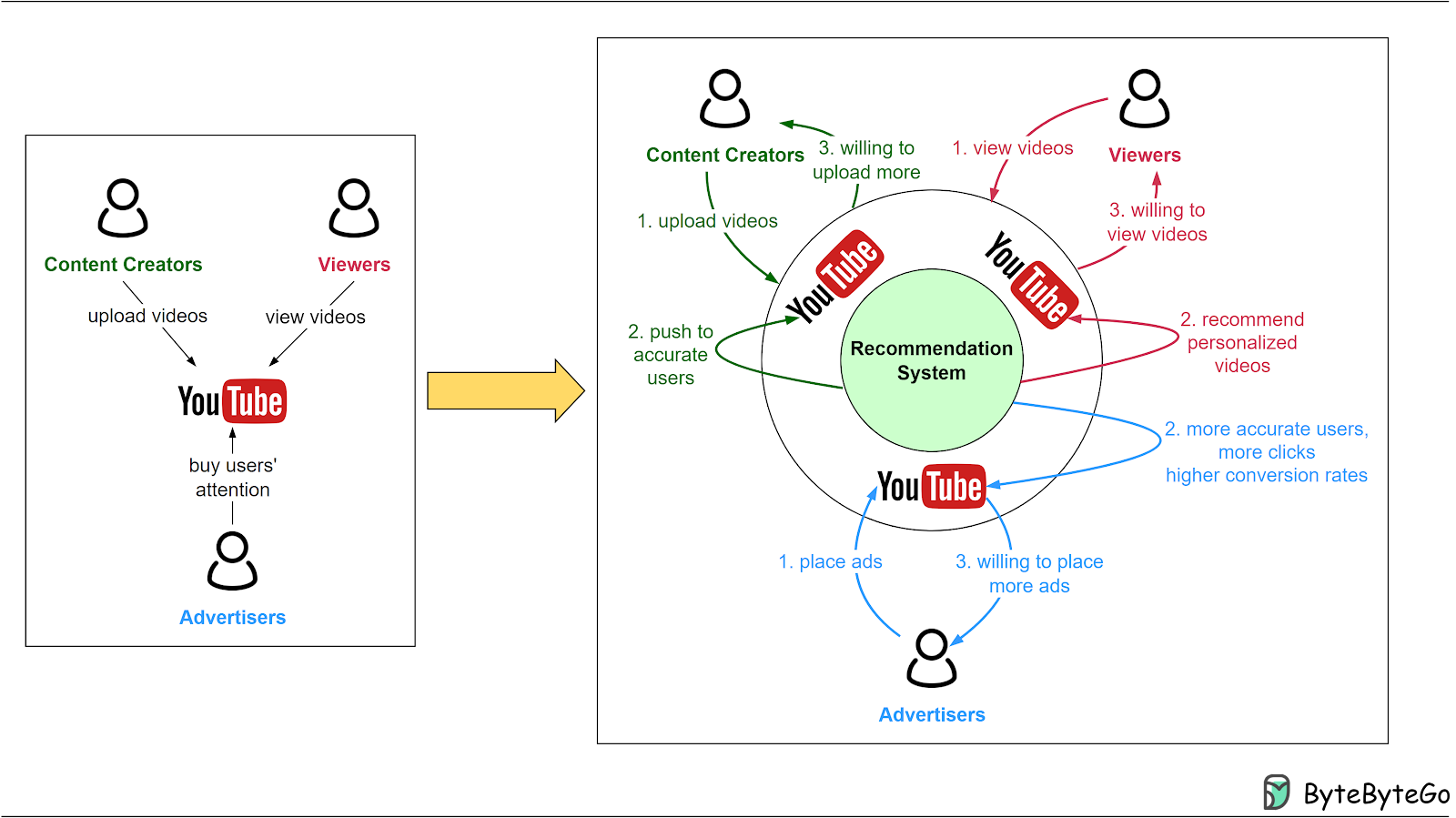
Without recommendation systems, viewers would have to sift through content to find what interests them, while advertisers manually searched for their ideal audience. This made discovery cumbersome and less effective, with many views and advertisers missing out on potentially perfect matches.
Smart recommendation systems transform the experience by leveraging algorithms that analyze various data points – view history, user profiles, trending topics, and recommendations from friends – to personalize content for viewers. This tailored approach means viewers are more likely to engage deeply with content, encouraging creators to produce more and advertisers to invest more, thanks to better targeting and higher conversion rates.
Consider an e-commerce giant like Amazon, where recommendation systems personalize product suggestions. Even a 1% improvement in their recommendation accuracy can translate into tens of millions in sales revenue daily. This massive impact underscores why major companies continually invest in enhancing their recommendation algorithms and models.
The investment in recommendation systems isn't just about boosting sales or viewer numbers; it's about enriching user experiences and fostering user retention. These systems are designed to understand and anticipate user preferences which create a more engaging and personalized online experience.
Now that we understand the role of a recommendation system in enhancing a business’s ecosystem, let’s dive deeper into how these systems curate content for us.
At the heart of a recommendation system is a deep-learning model designed to predict user preferences for specific videos. This involves scoring and ranking videos, integrating advertisements, and generating the final set of recommendations. Unlike simpler models, a deep learning-based system can more accurately mimic the complex process of human decision-making for content selection.
To train the model to predict user preferences accurately, it’s essential to analyze data from three key sources:
Videos: Considering the vast size of video data, the model leverages various attributes such as video descriptions, tags, actual content, and viewer impressions to derive video features.
Users: Understanding user preferences is crucial. This is achieved by analyzing static data, like user profiles, and dynamic data, including interaction patterns like clicks and social network interactions.
Context: Contextual factors, such as location and time, deeply impact content preferences. The model considers these elements to fine-tune its suggestions.
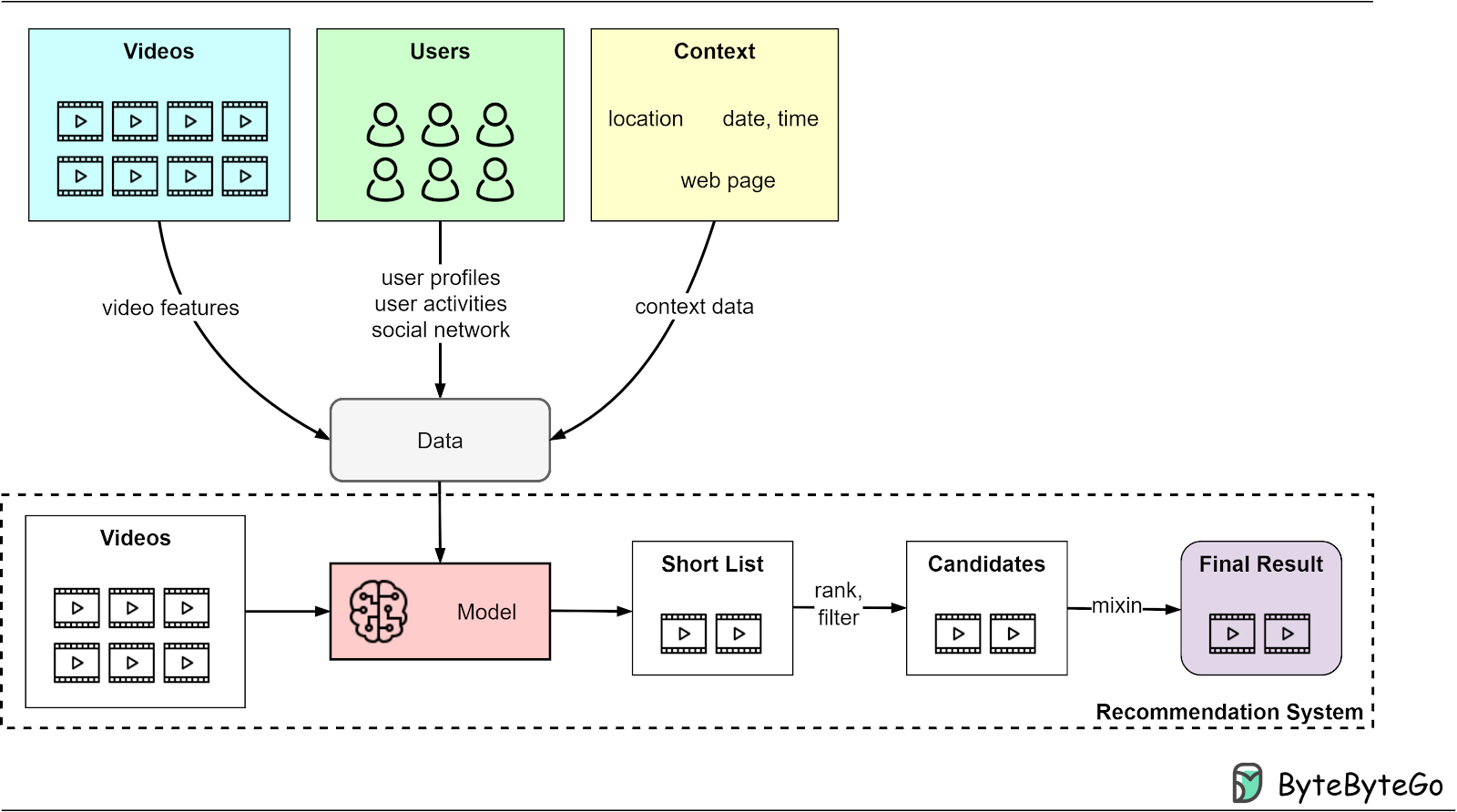
The complexity of a recommendation system from an engineering perspective goes beyond these elements. We’ll explore the system design aspects in the next few sections.
In a nutshell, the design of recommendation systems rests on three core pillars:
Data
Model
Serving
The precision of a recommendation system hinges on the quality of its underlying data. However, harnessing this data comes with its own set of challenges:
Data size: The sheer volume of data that recommendation systems need to sift through presents significant technical hurdles in terms of data storage, retrieval, and processing. To manage this, technologies related to big data are used to handle massive datasets efficiently.
Data definition and feature extraction: Determining what data to use is critical. This involves collaboration between domain experts and data scientists to identify the most relevant attributes from user, product, and contextual data. Much of this data is unstructured, such as videos and comments, and cannot be used in its raw form. Instead, it undergoes a process to be converted into “embeddings” – high-dimensional representations of the data. This process, known as feature engineering, is crucial for preparing data for subsequent analysis.
Real-time processing: Beyond the challenges of managing large datasets, the recommendation system needs to process the data in near real-time. This ensures the system can make recommendations based on the latest user activities and content updates, capturing the dynamic nature of trends as they happen.
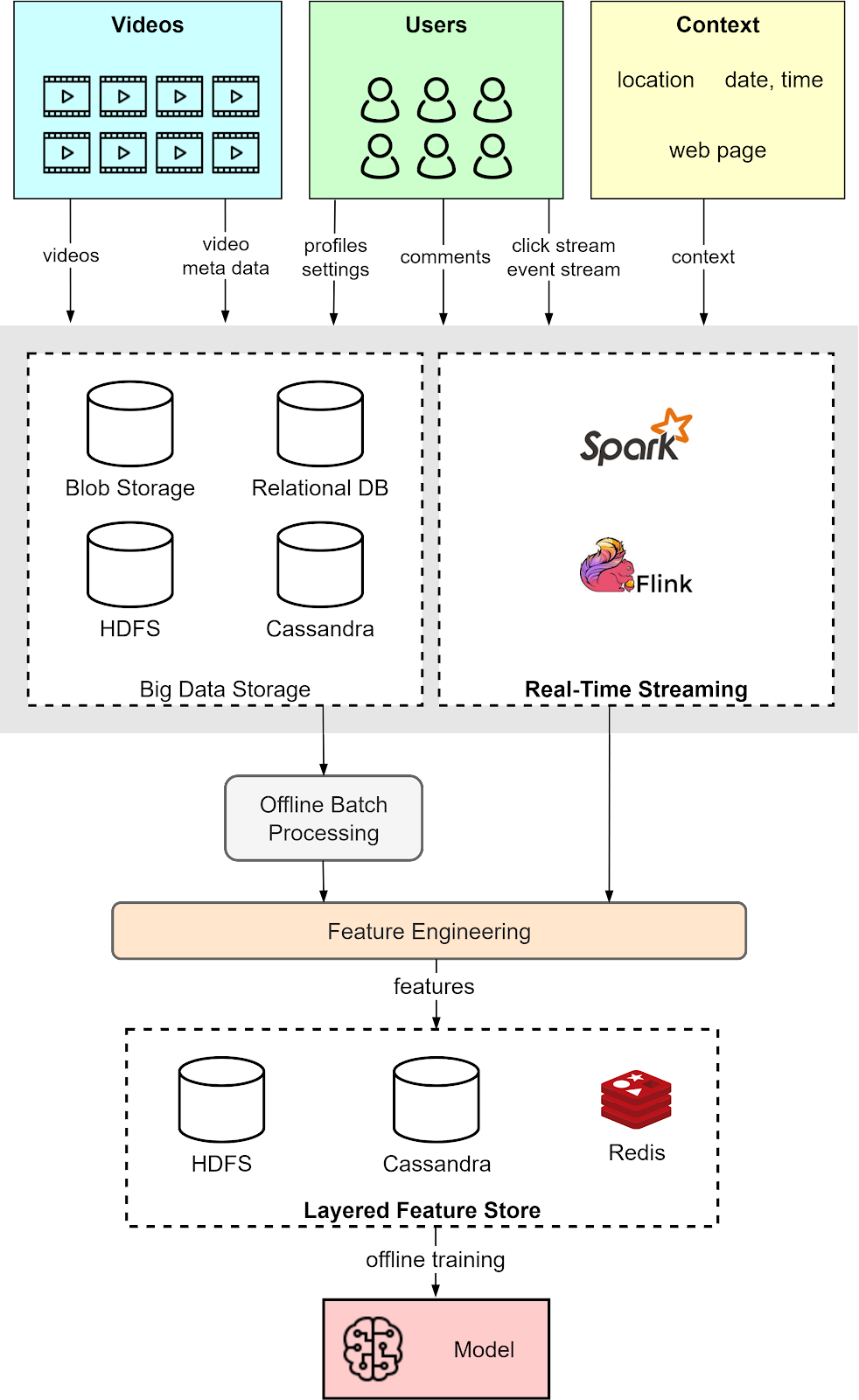
A typical architecture for processing data within a recommendation system involves layers designed to handle the diversity and scale of data. This includes big data storage solutions capable of accommodating various data types, from video blobs and user comments to structured relational data to wide-column data like user profiles. For time-sensitive information like user clicks, streaming platforms such as Spark or Flink are used to ensure that recommendations reflect the most current user behaviors.
In this architecture, features derived from batch and streaming data are organized in storage tiers. This might involve using HDFS for the least accessed features, Cassandra or DynamoDB for less frequently accessed data, and caching mechanisms for data that is regularly queried. Such a structured approach to data architecture facilitates more efficient model training and enhances the system’s ability to deliver timely and relevant recommendations.
Feature engineering plays a pivotal role in translating raw data into a format machine learning models can understand and use. Let’s break down what features and embeddings are and explore the process of feature engineering.
Features are attributes or variables extracted from raw data, which serve as inputs for machine learning models to perform predictions. These models don't directly interpret the raw data collected, such as videos, user information, and contextual data. We need to extract this data into numeric information that reflects specific aspects of the business domains.
Consider a video recommendation scenario. The system might base its recommendations on factors such as the user’s interest in a video, subscription to the channel, or previous interactions with similar content.
Translating these factors into numeric features could look something like this:
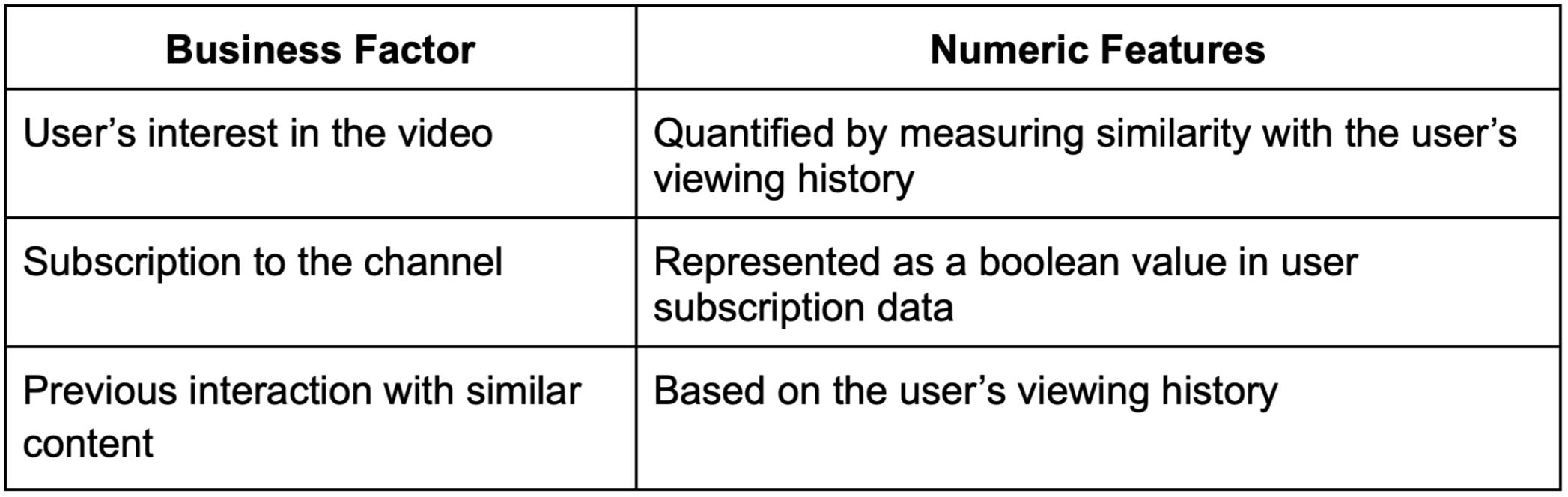
The concept of “similarity” is abstract and is mathematically represented through embeddings. Embeddings are high-dimensional vectors that encapsulate the essence of objects, allowing data scientists to compute similarity as the distance between these embeddings in the vector space. Let’s see how it works.
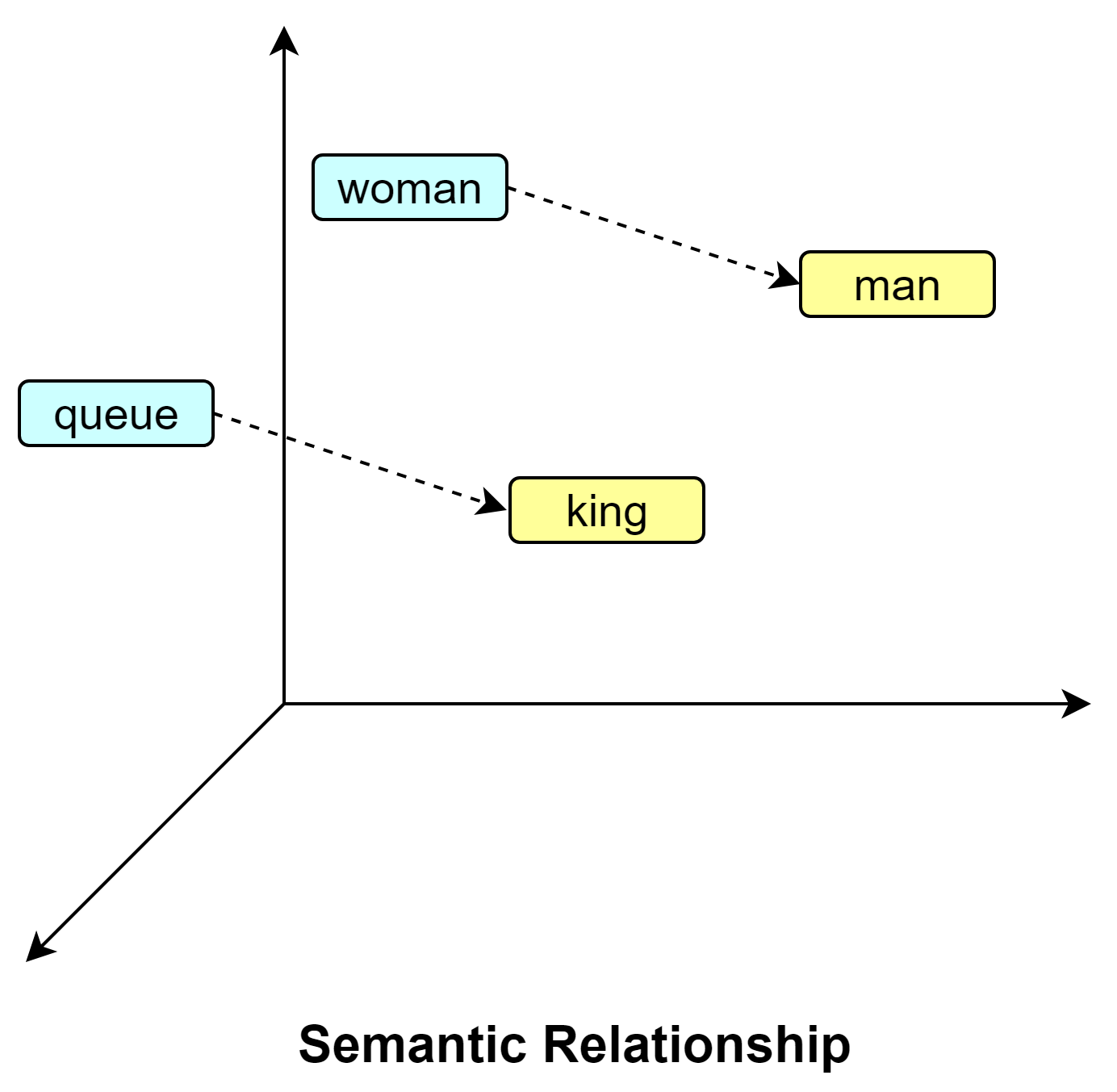
Word2Vec, developed by Tomas Mikolov and his team at Google in 2013, is a groundbreaking technique for generating word embeddings. It maps words into a dense vector space where semantically similar words are positioned closely together.
For instance, in the vector space created by Word2Vec, the relationship between “man” and “woman” mirrors the relationship between “king” and “queen.” This similarity in positioning illustrates the model’s ability to understand semantic relationships, including gender differences in this case.
Additionally, Word2Vec facilitates operations on words as if they were vectors in a mathematical space. A well-known example that showcases this feature is the equation:
"king" - "man" + "woman" = "queen"
This equation demonstrates Word2Vec’s power to comprehend and manipulate complex semantic relationships within its vector space. It is a foundational tool in many NLP and machine learning tasks.
Word2Vec transforms word sequences into embeddings based on the context in which they appear. Item2Vec leverages similar ideas to transform sequences of data, such as a user’s viewing history, into embeddings.
The key benefit of Item2Vec for recommendation systems is its ability to understand similarities between items based on usage patterns. Once these embeddings capture relationships between items, Item2Vec can then suggest new items that a user may be interested in based on their past interactions.
For example, in a video streaming platform, Item2Vec could analyze a user's watching behavior to find connections between the types of videos they have viewed. It could then recommend new unwatched videos that are close to the user's typical preferences. This allows hyper-personalized recommendations beyond relying on content metadata alone.
In this issue, we traced the evolution of information retrieval on the internet, from early search engines to modern recommendation platforms that rely on sophisticated data analysis and machine learning.
Central to this is managing and extracting value from massive volumes of data. Maintaining data quality is crucial for effective recommendations. Many companies now use data lakes to support both recommendations and business intelligence. Streaming infrastructure like Spark and Flink channels real-time data to enable near-instant recommendations that reflect the latest user behaviors - vastly improving the user experience on platforms like YouTube.
We explored how raw data gets transformed into features to power recommendations. Storing these features efficiently using caching techniques allows quick access to frequently used data. Some features are best represented by a technique called embedding, which turns similarity into distance in high-dimensional space - improving content understanding and relationships.
In the next issue, we will cover how the deep learning model is trained with the data and features and how a recommendation engine runs in production. Stay tuned!