This week’s system design refresher:
OAuth 2 explained in simple terms (Youtube video)
Comparison of URL, URI, and URN
Data Warehouse vs Data Lake
Twitter 1.0 Tech Stack
Sponsor us
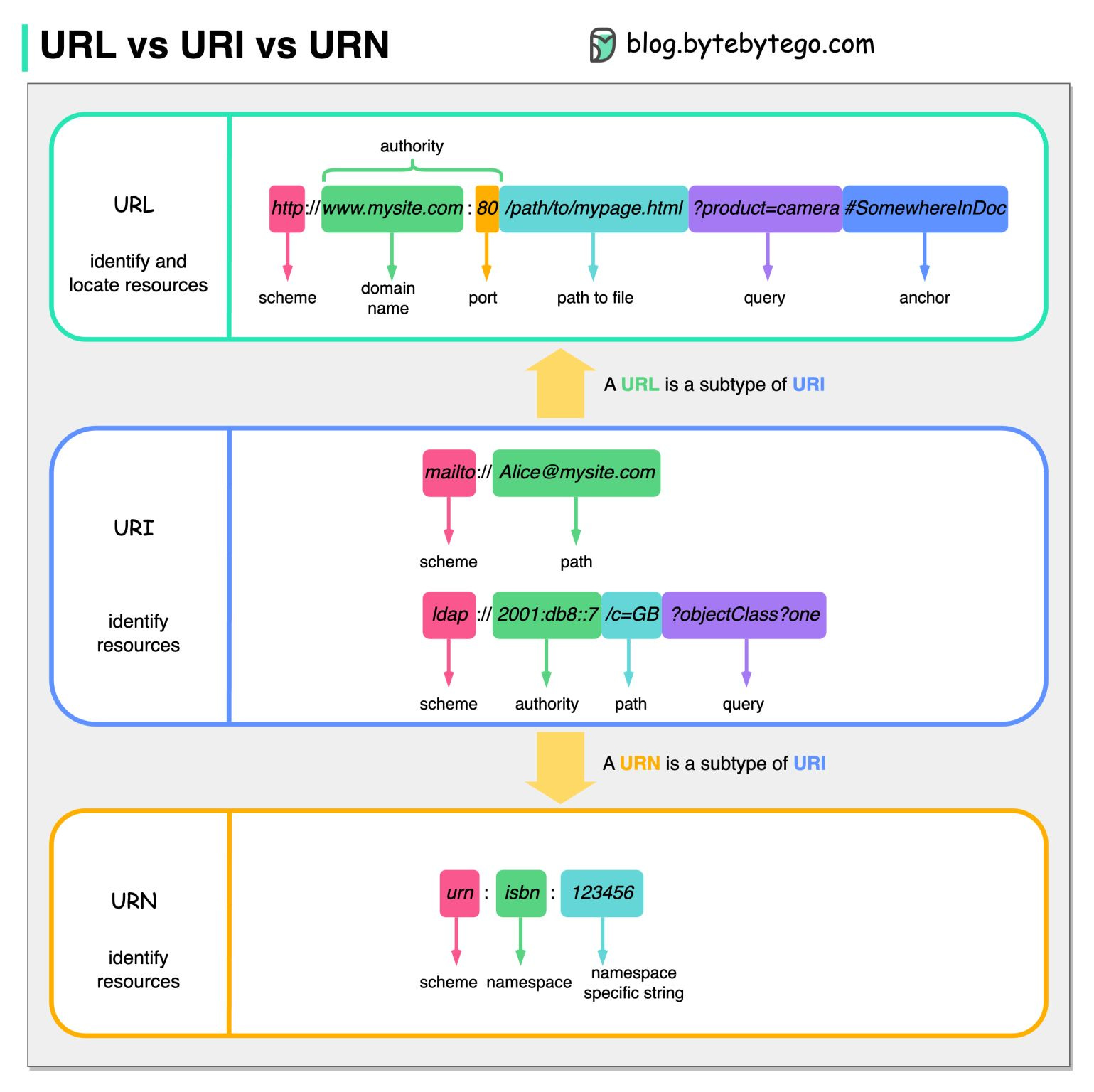
The diagram below shows a comparison of URL, URI, and URN.
URI
URI stands for Uniform Resource Identifier. It identifies a logical or physical resource on the web. URL and URN are subtypes of URI. URL locates a resource, while URN names a resource.
A URI is composed of the following parts:
scheme:[//authority]path[?query][#fragment]
URL
URL stands for Uniform Resource Locator, the key concept of HTTP. It is the address of a unique resource on the web. It can be used with other protocols like FTP and JDBC.
URN
URN stands for Uniform Resource Name. It uses the urn scheme. URNs cannot be used to locate a resource. A simple example given in the diagram is composed of a namespace and a namespace-specific string.
If you would like to learn more detail on the subject, I would recommend W3C’s clarification.
The diagram below shows their comparison.
A data warehouse processes structured data, while a data lake processes structured, semi-structured, unstructured, and raw binary data.
A data warehouse leverages a database to store layers of structured data, which can be expensive. A data lake stores data in low-cost devices.
A data warehouse performs Extract-Transform-Load (ETL) on data. A data lake performs Extract-Load-Transform (ELT).
A data warehouse is schema-on-write, which means the data is already prepared when written into the data warehouse. A data lake is schema-on-read, so the data is stored as it is. The data can then be transformed and stored in a data warehouse for consumption.
Over to you: Do you use a data warehouse or a data lake to retrieve data?
This post is based on research from many Twitter engineering blogs and open-source projects. If you come across any inaccuracies, please feel free to inform us.
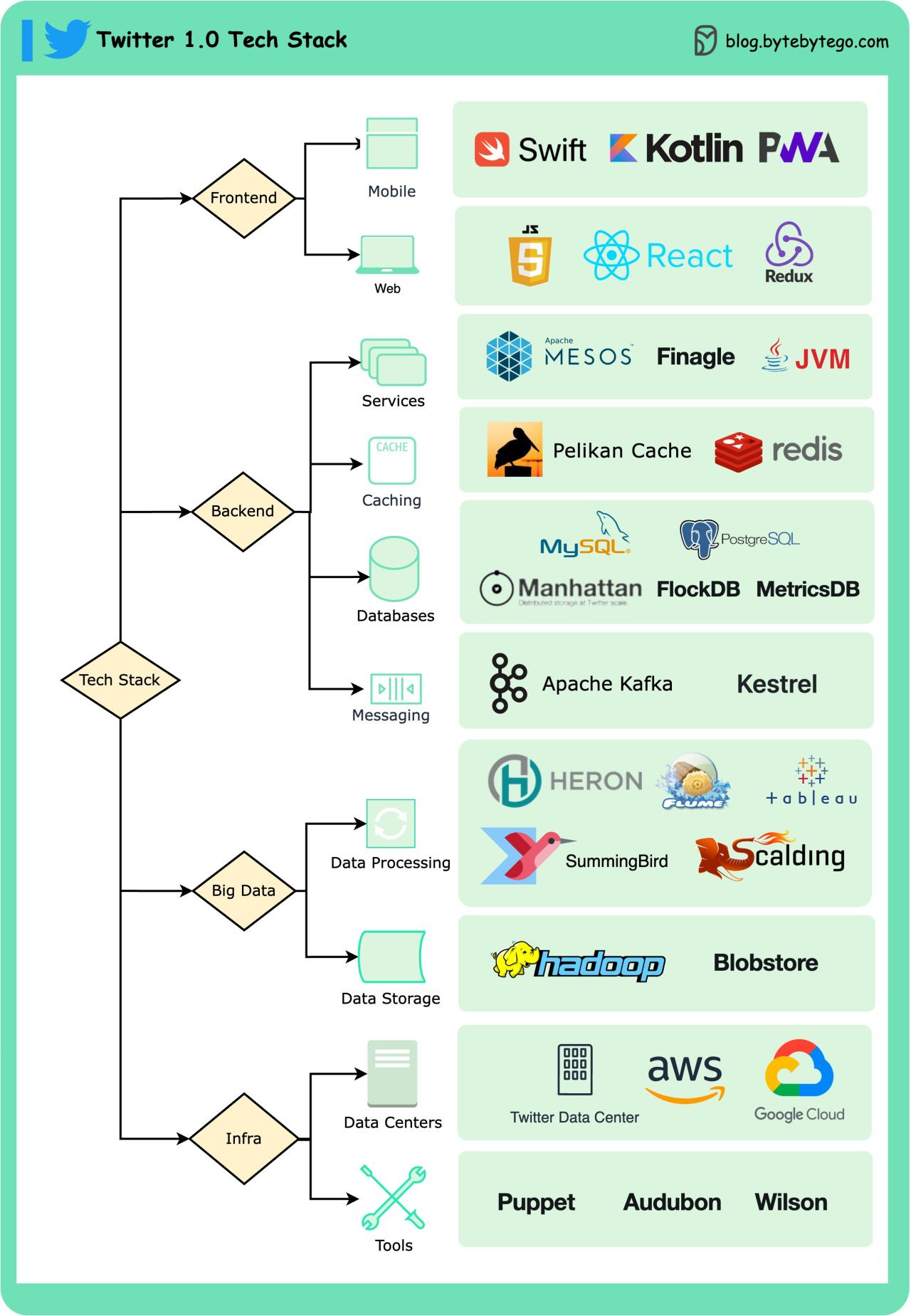
Mobile: Swift, Kotlin, PWA
Web: JS, React, Redux
Services: Mesos, Finagle
Caching: Pelikan Cache, Redis
Databases: Manhattan, MySQL, PostgreSQL, FlockDB, MetricsDB
Message queues: Kafka, Kestrel
Data processing: Heron, Flume, Tableau, SummingBird, Scalding
Data storage: Hadoop, blob store
Data centers: Twitter data center, AWS, Google Cloud
Tools: Puppet, Audubon, Wilson
📈 Feature your product in the biggest technology newsletter on Substack
ByteByteGo is the biggest technology newsletter on Substack with over 450,000 readers working at companies like Apple, Meta, Amazon, Google, etc. They have the influence and autonomy to make large purchase decisions. Learn more today.