Welcome to the final part of our series on mastering database selection. In the first two parts, we learned the basics of databases and important factors for choosing one. Now, in Part 3, we'll apply this knowledge together.
We'll go through key steps in the database selection process. We'll assess our project needs, explore database options, test performance, and consider long-term effects. By the end, we'll make a well-informed choice for our project's success.
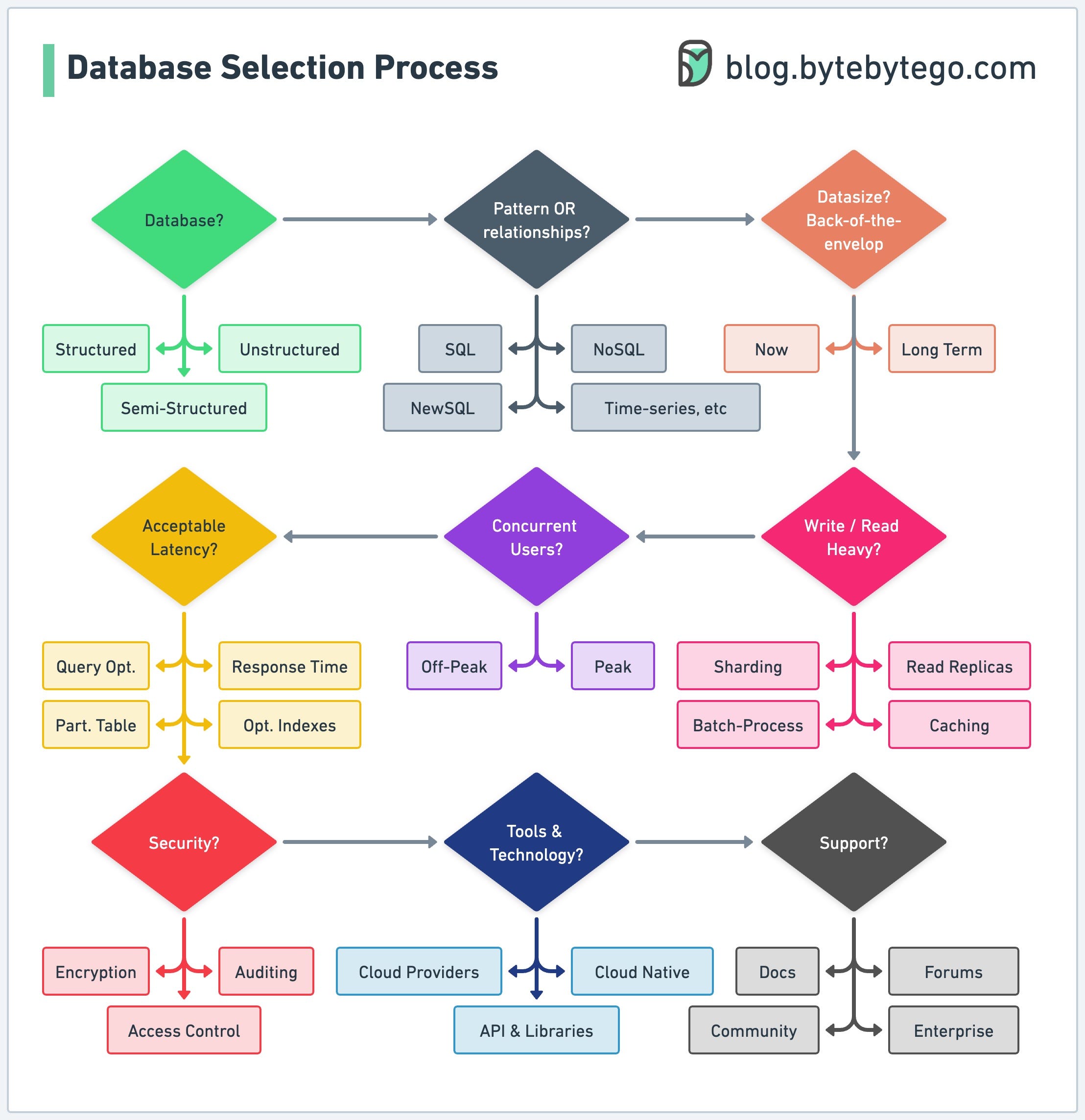
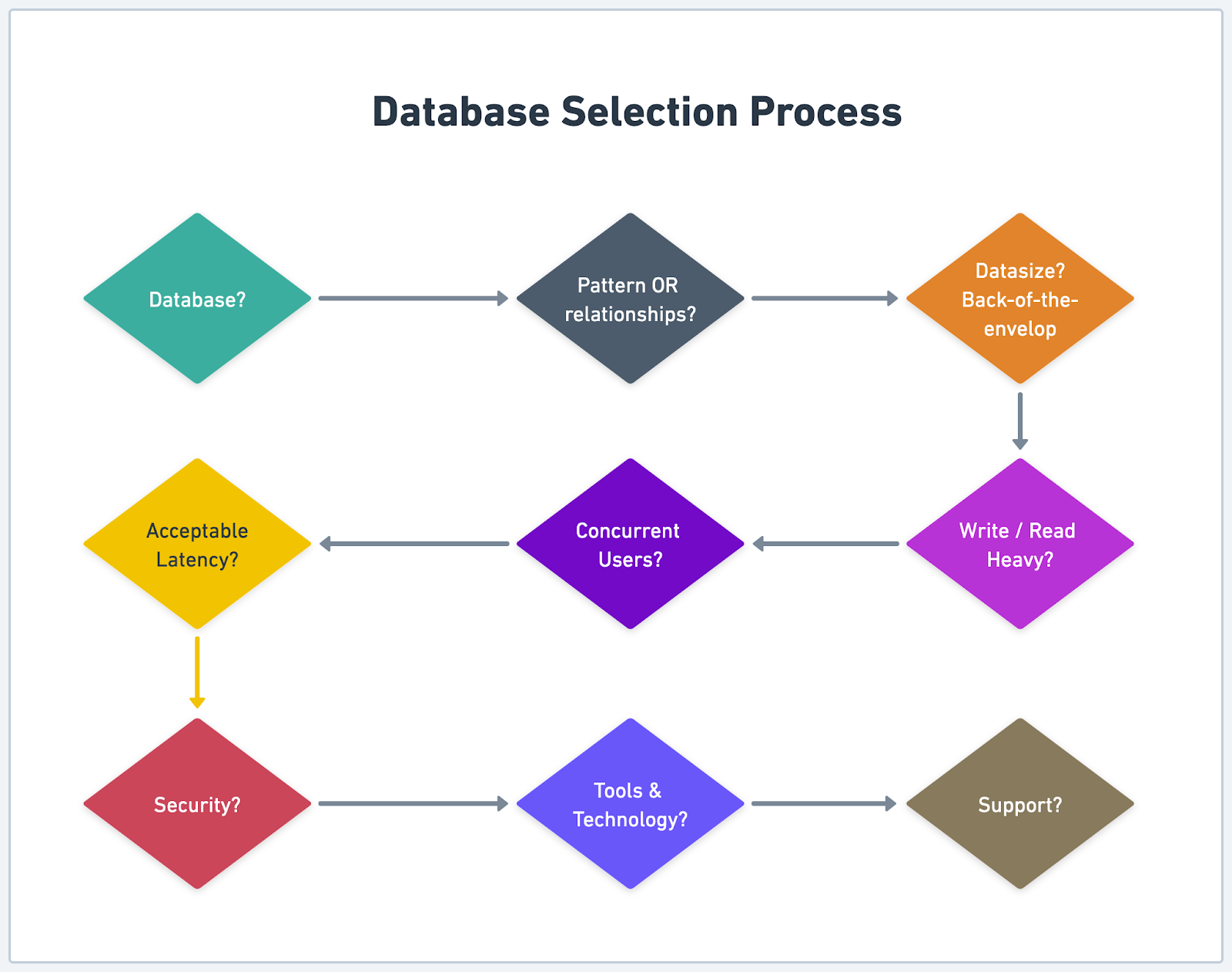
First, let’s examine the types of data our project will handle. Identify whether we will be working with structured, semi-structured, or unstructured data, and determine if the data contains specific patterns or relationships that need to be captured. Understanding the nature of the data will help us decide which type of database is more appropriate.
Next, we should consider the expected volume of data the project will generate, both now and in the future. Estimate the amount of storage required and the rate at which new data will be added. This information will inform our decision on whether we need a database with high write performance or one that can handle large amounts of data efficiently.
Another essential aspect of project requirements is the anticipated number of concurrent users or connections. Determine the maximum number of users or connections the database must support, and how the demand may fluctuate during peak and off-peak periods. This will help us select a database that can scale to meet these demands without compromising performance.
We should also carefully assess performance and security requirements. Identify any specific performance metrics, such as response time or query efficiency, that are critical to the project's success. Additionally, let’s take note of any regulatory or compliance requirements that may necessitate specific security features, such as encryption, access controls, or auditing capabilities.
Finally, consider any existing systems, tools, or technologies that will need to integrate with the chosen database. We should identify any potential compatibility issues or integration challenges that may arise, and determine if the database options under consideration offer support for integration with our existing technology stack.
By thoroughly assessing the project requirements, we’ll have a solid foundation upon which to build as we research, evaluate, and ultimately select the most suitable database for our needs. This groundwork will serve as a valuable guidepost throughout the remainder of the database selection process, ensuring that the final choice aligns with the unique requirements of our project.
Next, let’s dive into researching and evaluating the available database options. We’ll start by creating a shortlist of potential database candidates that align with the project requirements. Using our knowledge of different database types, their characteristics, and use cases, we’ll identify the most suitable options. This shortlist will serve as the starting point for a more in-depth evaluation of each database.
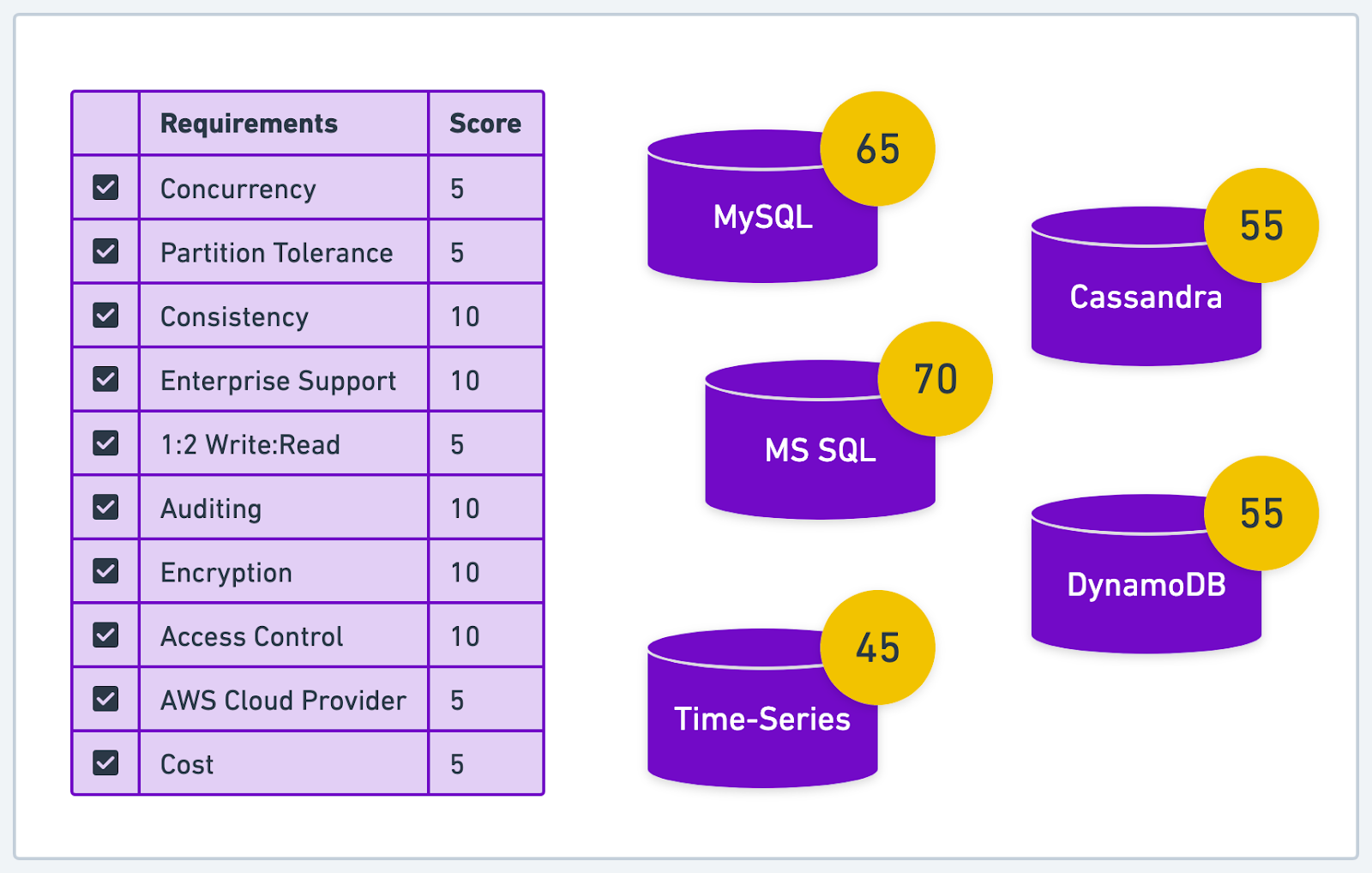
For each database on our shortlist, we’ll investigate its features and capabilities in relation to the project's needs. Analyze how well each option addresses the various factors we discussed earlier, such as scalability, performance, data consistency, data model, security, cost, and community support. It is important to take note of any trade-offs or limitations that may impact the project's success.
To gain insight into the real-world performance of each database, we’ll consult user reviews, case studies, and expert opinions. Look for information on how the database performs in similar projects or industries, and consider any challenges or successes experienced by others. This will help us develop a more comprehensive understanding of each option's strengths and weaknesses.
Additionally, consider each database's ecosystem and the resources available for developers. We’ll evaluate the quality and accessibility of documentation, tutorials, and support forums. A strong community and a wealth of resources can be invaluable in helping us overcome any challenges that may arise during implementation and maintenance.
As we research and evaluate each database, it's important to keep the project requirements in mind and stay focused on finding the best match for our specific needs. By conducting a thorough investigation of each database on the shortlist, we'll be better prepared to make an informed decision and choose the right database for the project.
Once we have a shortlist, it's time to conduct performance testing and benchmarking. We’ll create a testing environment that closely resembles the production environment. This includes setting up the same hardware, software, and network configurations that we expect to use in the actual project. This will help ensure that the performance tests and benchmarks provide accurate and relevant results.
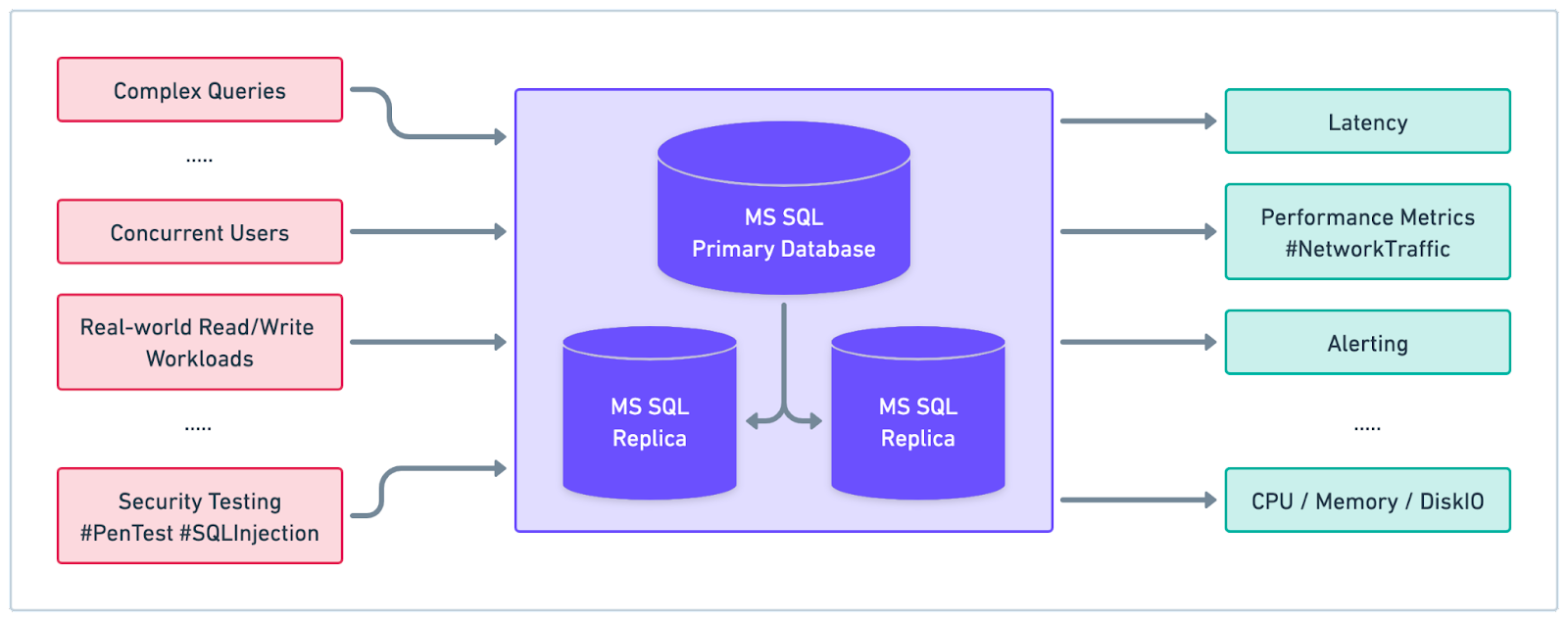
Next, we’ll design test scenarios that simulate realistic workloads for the project. These scenarios should cover a variety of use cases, such as reading and writing data, processing complex queries, and handling concurrent users or connections. By testing the databases under conditions that mirror real-world situations, we can better assess their performance and suitability for the project.
During testing, measure and compare key performance metrics for each database, such as query efficiency, read and write performance, and overall system responsiveness. We’ll record the results for each test scenario and use them to create a comprehensive performance profile for each database option.
Once we have completed the performance testing and benchmarking, analyze the results to identify any trends or patterns. We’ll look for areas where a particular database excels or struggles, and consider how these strengths and weaknesses align with the project requirements. Keep in mind that no database is perfect, and some trade-offs may be necessary to achieve the best overall fit for the needs.
A thorough performance testing and benchmarking can help us gain a deeper understanding of how each database on the shortlist will perform in the project environment. This step is critical. It will help us make a more informed decision and ultimately choose the database that offers the best performance and reliability for the specific use case.
When evaluating the various databases, it is important to consider the long-term implications of the decision. We should think about how the project might change in the future. Factors such as increases in data volume, user traffic, and the addition of new features or functionality should be taken into account. We need to assess how these changes might impact the performance, scalability, and maintenance requirements of the chosen database.
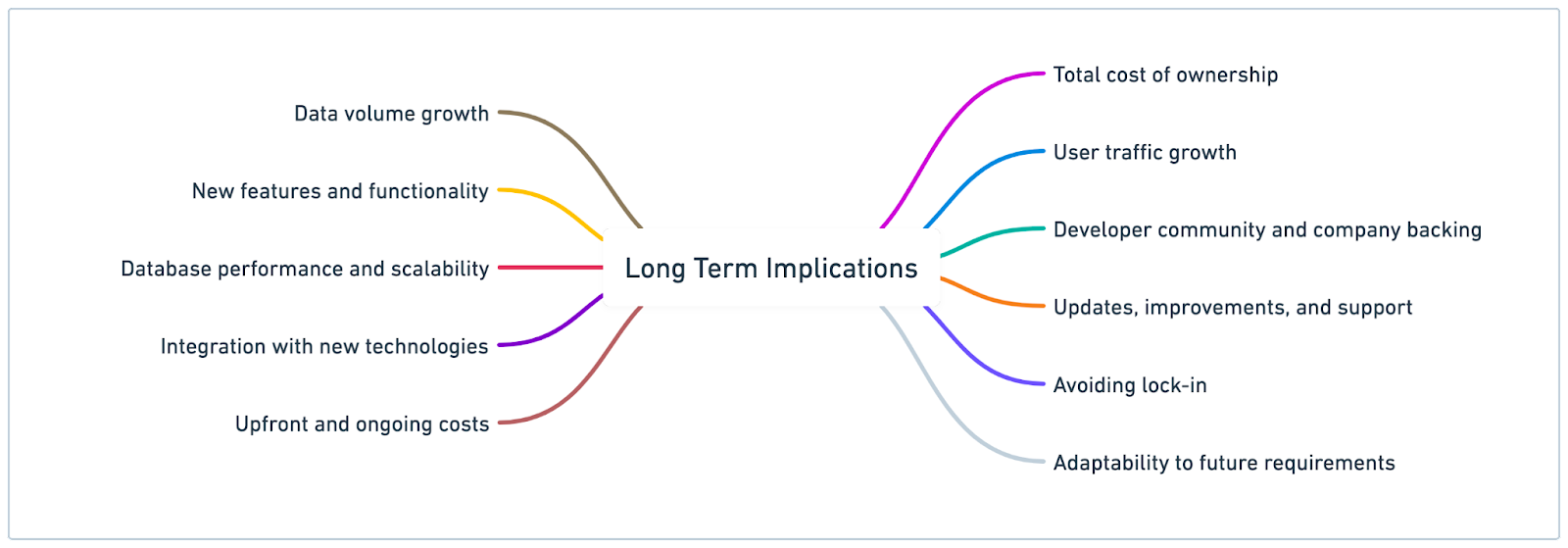
As we evaluate the databases on the shortlist, assess their ability to adapt to these anticipated changes. For example, can the database handle a significant increase in data volume without compromising performance? Is it capable of scaling to accommodate more concurrent users or connections? Will it be able to integrate with new technologies or services that may become part of the project's ecosystem?
Another important aspect of long-term planning is the potential cost implications of the database choice. While some databases may have lower upfront costs, they could incur higher maintenance, management, or scaling expenses over time. We should consider the total cost of ownership for each database option, including both immediate and future expenses. This ensures that the decision remains cost-effective in the long run.
Lastly, we need to examine the stability and future prospects of each database's developer community and company backing. A thriving community and strong company support can indicate a more stable and reliable future for a database. This can provide us with the confidence that the chosen solution will continue to receive updates, improvements, and support as the project grows.
After carefully considering all the factors and conducting thorough evaluations, it's time to make the final choice. Start by reviewing the information we have gathered throughout the selection process. We’ll compare each database on the shortlist across the various factors we have discussed, such as scalability, performance, data consistency, data model, security, cost, and community support. Identify the strengths and weaknesses of each option and weigh them against the project's specific requirements.
As we analyze the findings, we should consider the trade-offs we may need to make to achieve the best overall fit for the project. It is unlikely that a single database will perfectly meet every requirement, so prioritizing the most critical aspects of the project will help guide the decision-making process.
Once we have thoroughly reviewed the findings and considered the trade-offs, we can make the final choice with confidence. Remember that our decision is based on a comprehensive understanding of the project's requirements and a thorough evaluation of the available options.
After selecting the database, it's important to continue monitoring its performance, scalability, and compatibility with the project's evolving needs. We should regularly evaluate how well the database is meeting the project's requirements and be prepared to make adjustments as necessary.
Making the final choice in the database selection process is a culmination of the hard work and thorough evaluation we have invested throughout the journey. By following the key steps we have discussed, we can make an informed decision that sets the project up for success, both in the present and into the future.
In this section, we will analyze three real-world case studies to highlight how different companies made successful database selection decisions. These examples will demonstrate the factors discussed earlier in action and help us appreciate the importance of making the right choice for a specific use case.
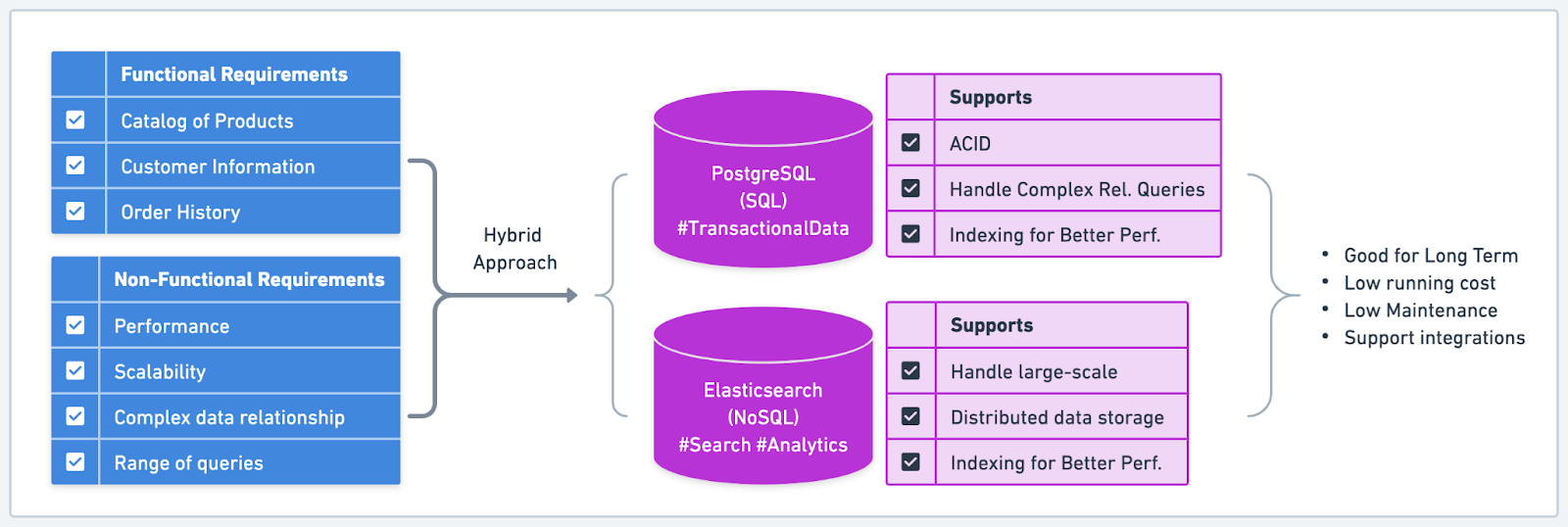
An e-commerce platform experienced rapid growth in its user base and needed a database solution to handle the expanding catalog of products, customer information, and order history. The primary considerations for this company were performance, scalability, support for complex data relationships, and the ability to accommodate a diverse range of queries.
Initially, the company considered using a single relational database to handle all of their data needs. However, they realized that while a relational database would be suitable for managing core transactional data, it might not offer the performance and flexibility required for search and analytics functions.
To address these concerns, the e-commerce platform evaluated several relational and NoSQL databases. They eventually decided on a hybrid approach, using a relational database (PostgreSQL) for their core transactional data and a NoSQL database (Elasticsearch) for search and analytics.
The choice of PostgreSQL for transactional data allowed the company to maintain ACID properties for critical operations, ensuring data consistency and reliability. PostgreSQL's robust indexing and querying capabilities also enabled the platform to handle complex data relationships, such as linking customers to their order history and managing product inventory.
On the other hand, Elasticsearch was selected for its powerful search capabilities and its ability to handle large-scale, distributed data storage. By using Elasticsearch, the e-commerce platform could quickly index and retrieve product data. This enhances the customer experience by providing real-time search results and personalized recommendations.Elasticsearch's scalability ensured that the platform could continue to grow without performance bottlenecks.
The company also needed to consider the long-term implications of their decision. They needed a solution that would be easy to maintain and evolve with their business needs. The thriving communities and ecosystem surrounding both PostgreSQL and Elasticsearch played a significant role in their decision. They provided valuable resources, support, and integration possibilities.
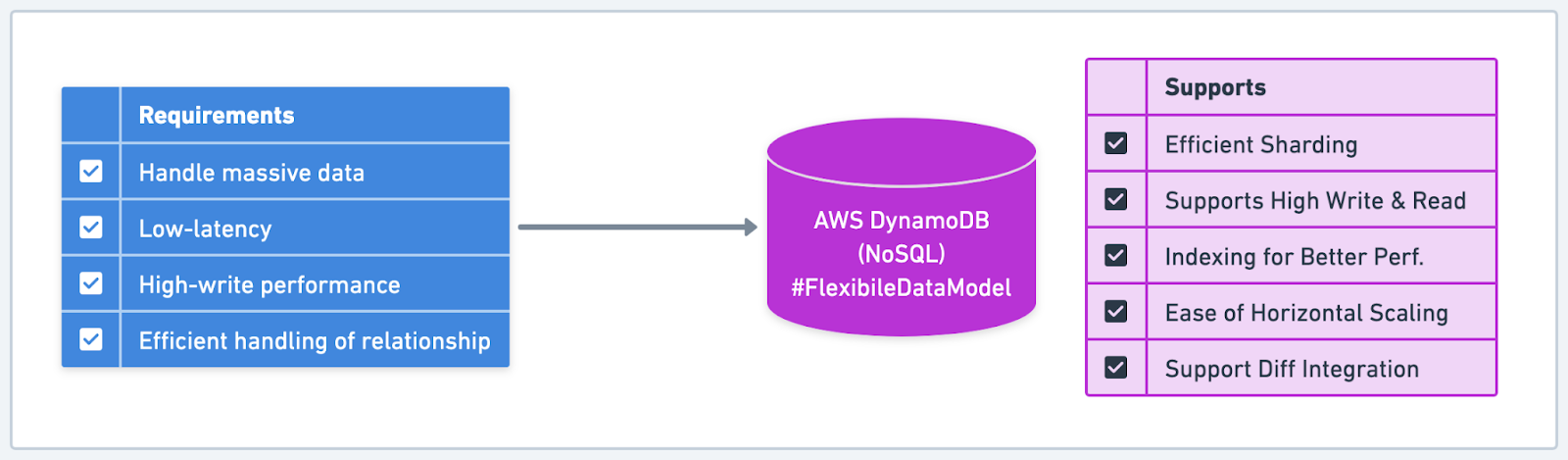
A social media platform with millions of users generating billions of interactions daily required a database solution capable of handling massive amounts of data while providing low-latency query responses. They needed a database with high write performance, efficient handling of relationships between users and content, and the ability to scale horizontally as the platform continued to grow.
At the outset, the company considered using traditional relational databases. However, they realized that modeling the complex relationships inherent in a social media platform, like friendships, comments, and shared content, would be challenging and potentially slow using a relational database model.
To address these concerns, the social media platform evaluated several NoSQL databases, focusing on their ability to represent complex data relationships and scale horizontally. After a thorough evaluation, they chose a distributed key-value store database (Amazon DynamoDB) due to its excellent performance, scalability, and flexible data modeling capabilities.
The choice of Amazon DynamoDB allowed the social media platform to efficiently store and retrieve user profiles, content, and relationships between them. By using a partition key to distribute data across multiple nodes, the platform could achieve high write and read performance, even at large scale. This performance enabled the platform to deliver a responsive user experience while accommodating constant growth and billions of interactions.
To model the complex relationships using Amazon DynamoDB, the company designed a creative data modeling approach.
The social media platform used the concept of adjacency lists to represent graph connections within DynamoDB. Adjacency lists are a way of representing graph connections in a table by storing the source node, target node, and the edge type as individual items. By using this approach, the platform could efficiently store and query complex relationships between users and content.
For example, to represent friendships between users, they created a table with a partition key representing the user ID and a sort key representing the friend's user ID. They also used a secondary index on this table with the friend's user ID as the partition key and the user ID as the sort key. This allowed them to query for all friends of a user and find all users who have a specific user as their friend.
To handle content, such as posts and comments, they created another table with a partition key representing the user ID and a sort key representing the content ID. To store the relationships between posts and comments, they used a composite sort key combining the content type (post or comment) and the content ID.
This design enabled the platform to efficiently query for all content created by a user, all comments on a specific post, or all posts a user commented on. With these carefully chosen partition and sort keys, they could distribute data evenly across the table, ensuring high write and read performance.
Amazon DynamoDB's horizontal scalability ensured that the platform could handle the ever-growing volume of data and user interactions without compromising performance. One downside was that data modeling in Amazon DynamoDB for high performance was unconventional, and the learning curve was quite steep.
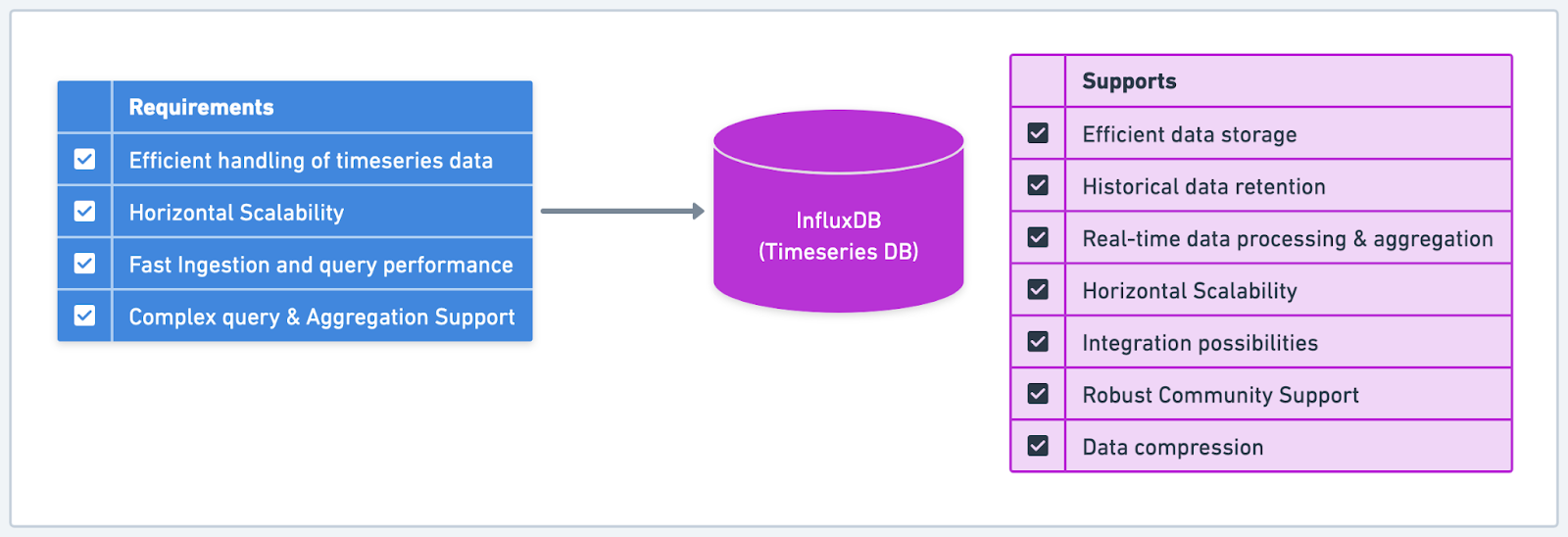
An IoT data processing platform collects and processes data from millions of connected devices, including sensors, appliances, and vehicles. The platform needs to handle high volumes of time-series data, process it in real-time, and provide low-latency access to the processed data for analytics and reporting.
Considering the unique requirements of their use case, the platform required a database that could handle large volumes of time-series data efficiently, scale horizontally, and provide fast data ingestion and query performance. They also needed a solution that could support complex queries and aggregations. These features are essential for analyzing and gaining insights from the data.
After evaluating various database solutions, they selected a time-series database, InfluxDB, as the best fit for their requirements. InfluxDB is designed specifically for handling time-series data. It offers optimized data storage and high-performance query capabilities.
With InfluxDB, the IoT platform benefited from a database that efficiently stored time-series data using a specialized data model, significantly reducing the storage space required compared to traditional databases. InfluxDB's data compression and efficient storage format allowed the platform to retain vast amounts of historical data without compromising on performance.
InfluxDB also provided built-in support for continuous queries, which enabled the platform to perform real-time processing and aggregation of incoming data streams. This feature allowed the IoT platform to pre-process data, reducing the load on downstream analytics and reporting systems and providing low-latency access to the processed data.
The platform leveraged InfluxDB's horizontal scalability to accommodate the increasing volume of data generated by their growing number of connected devices. As the data load increased, they could scale out by adding more nodes to their InfluxDB cluster.
The robust community and ecosystem surrounding InfluxDB, including extensive documentation, support, and integration possibilities with other tools, played a crucial role in their decision.
These case studies demonstrate that there is no one-size-fits-all solution when it comes to database selection. Each use case has its unique requirements, and the right choice depends on a deep understanding of those requirements and how various database types can fulfill them. By following the steps and considering the factors discussed throughout this series, we can make informed decisions that lead to the successful implementation of our database systems.
Throughout this three-part series, we have emphasized the significance of selecting the right database for our software development projects. Databases lie at the heart of any application, and the choice of the appropriate one can make or break its success. By understanding the various database types, considering the factors that influence selection, and following the key steps in the selection process, we can make informed decisions that enhance our applications' performance, scalability, and security.
We have explored the different types of databases and their strengths and weaknesses. We have also drilled into the factors that should guide our database selection, such as scalability, performance, data consistency, data model, security, cost, and community and ecosystem.
The case studies have shown that successful database selection in real-world projects requires careful analysis of project requirements and a deep understanding of the database options available.
As we conclude, we hope that this comprehensive guide has provided you with valuable insights and a solid foundation for mastering the art of database selection. Armed with this knowledge, we are better equipped to navigate the complex landscape of database technologies and make informed decisions that will benefit our projects and ultimately, our users.