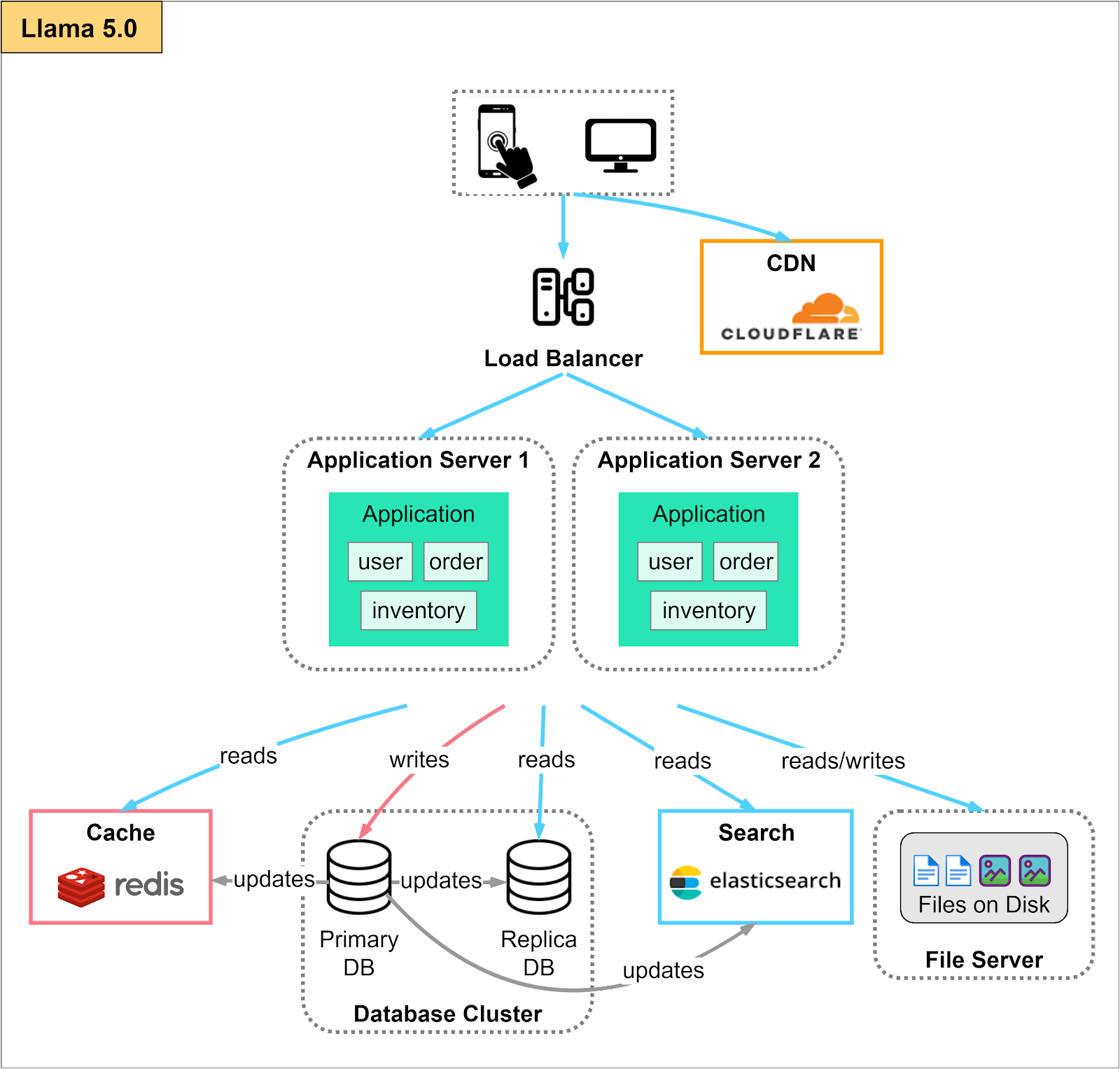
After implementing the primary-replica architecture, most applications should be able to scale to several hundred thousand users, and some simple applications might be able to reach a million users.
However, for some read-heavy applications, primary-replica architecture might not be able to handle traffic spikes well. For our e-commerce example, flash sale events like Black Friday sales in the United States could easily overload the databases. If the load is sufficiently heavy, some users might not even be able to load the sales page.
The next logical step to handle such situations is to add a cache layer to optimize the read operations.
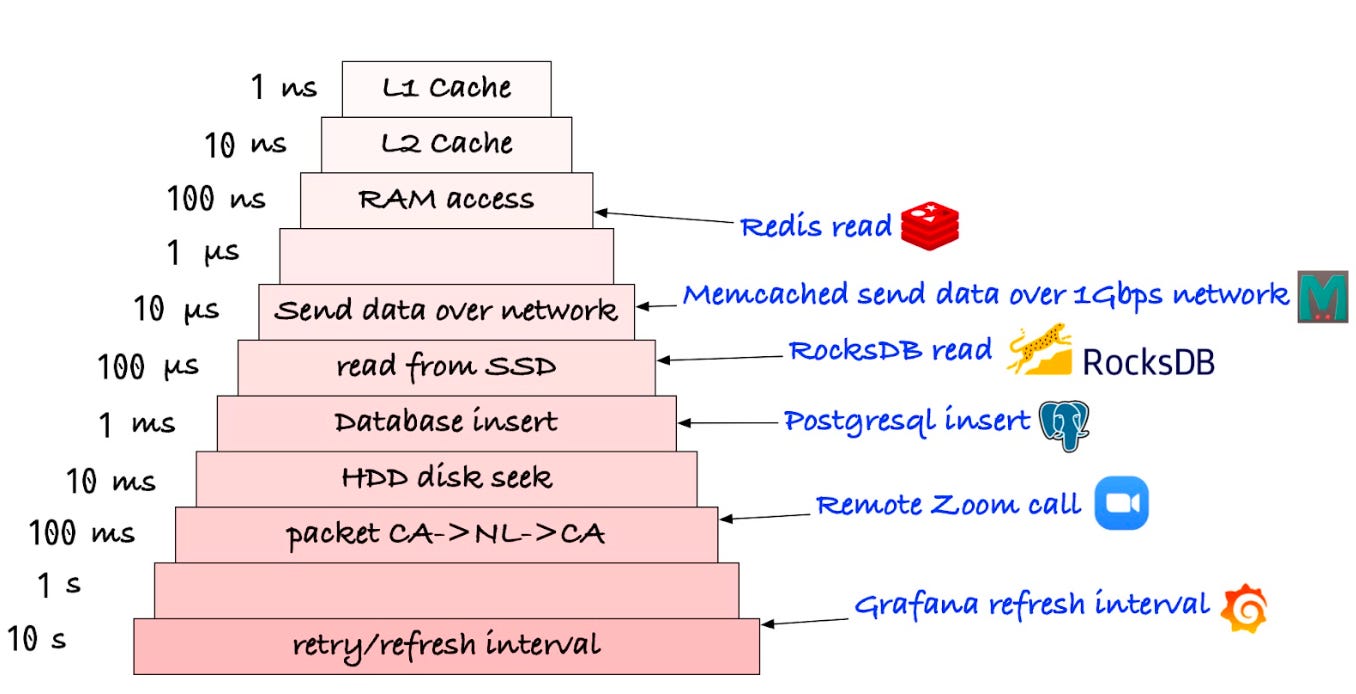
Redis is a popular in-memory cache for this purpose. Redis reduces the read load for a database by caching frequently accessed data in memory. This allows for faster access to the data since it is retrieved from the cache instead of the slower database. By reducing the number of read operations performed on the database, Redis helps to reduce the load on the database cluster and improve its overall scalability. As summarized below by Jeff Dean et al, in-memory access is 1000X faster than disk access.
For our example application, we deploy the cache using the read-through caching strategy. With this strategy, data is first checked in the cache before being read from the database. If the data is found in the cache, it is returned immediately, otherwise, it is loaded from the database and stored in the cache for future use.
There are other cache strategies and operational considerations when deploying a caching layer at scale. For example, with another copy of data stored in the cache, we have to maintain data consistency. We will have a deep dive series on caching soon to explore this topic in much greater detail.
There is another class of application data that is highly cacheable: the static contents for the application, such as images, videos, style sheets, and application bundles, which are infrequently updated. They should be served by a Content Delivery Network (CDN).
A CDN serves the static content from a network of servers located closer to the end user, reducing latency, and improving the loading speed of the web pages. This results in a better user experience, especially for users located far away from the application server.
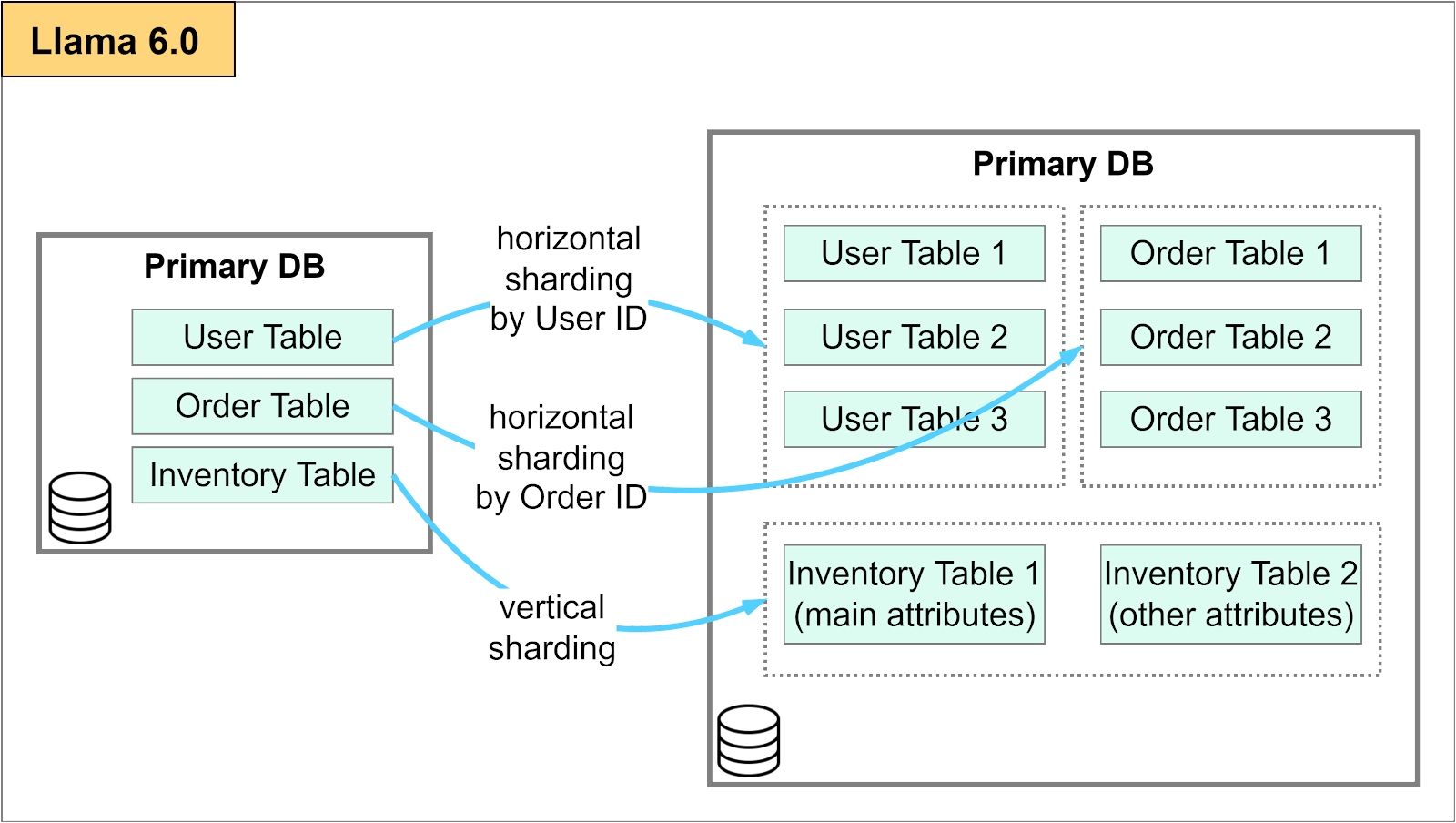
A cache layer can provide some relief for read-heavy applications. However, as we continue to scale, the amount of write requests will start to overload the single primary database. This is when it might make sense to shard the primary database.
There are two ways to shard a database: horizontally or vertically.
Horizontal sharding is more common. It is a database partitioning technique that divides data across multiple database servers based on the values in one or more columns of a table. For example, a large user table can be partitioned based on user ID. It results in multiple smaller tables stored on separate database servers, with each handling a small subset of the rows that were previously handled by the single primary database.
Vertical sharding is less common. It separates tables or parts of a table into different database servers based on the specific needs of the application. This optimizes the application based on specific access patterns of each column.
Database sharding has some significant drawbacks.
First, sharding adds complexity to the application and database layers. Data must be partitioned and distributed across multiple databases, making it difficult to ensure data consistency and integrity.
Second, sharding introduces performance overhead, increasing application latency, especially for operations that require data from multiple shards.
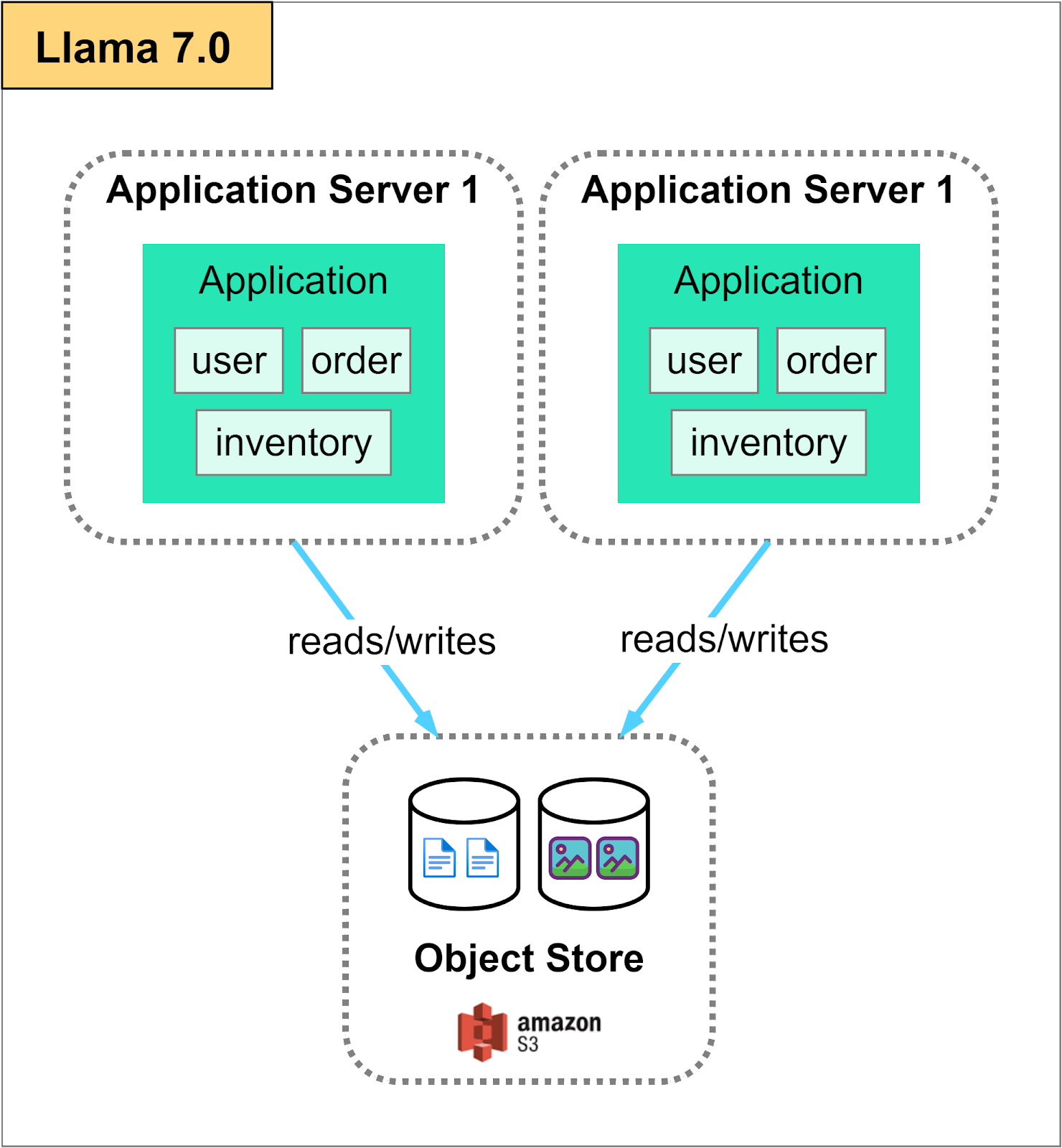
For some applications, static content is a significant part of the website. Even though they are already served by the CDN, they can overflow the file storage on the single file server.
Instead of scaling up the file server, it is a good idea to store these static files in a distributed object store like AWS S3.
An object store provides practically unlimited storage and strong durability. It offers an easy-to-use API for storing and retrieving files. It can directly act as the origin server for the CDN.
Now we have done optimizations for both the application layer and the storage layer. This application architecture should be able to handle a million users.
Assuming further explosive user growth requires a single service instance to handle more capacity, the application arrives at a stage where each service should be managed by a specialized team. We can split the modules into independent services deployed on separate application servers. The services are wrapped with a Remote Procedure Call (RPC) layer and communicate with each other via RPC. Common RPC frameworks include gRPC, Thrift, etc.
In a modular monolith, there is a strict boundary between different domains and all of the code powers a single application. This is a stage before full-fledged microservices and should satisfy most use cases. Shopify uses a similar approach.
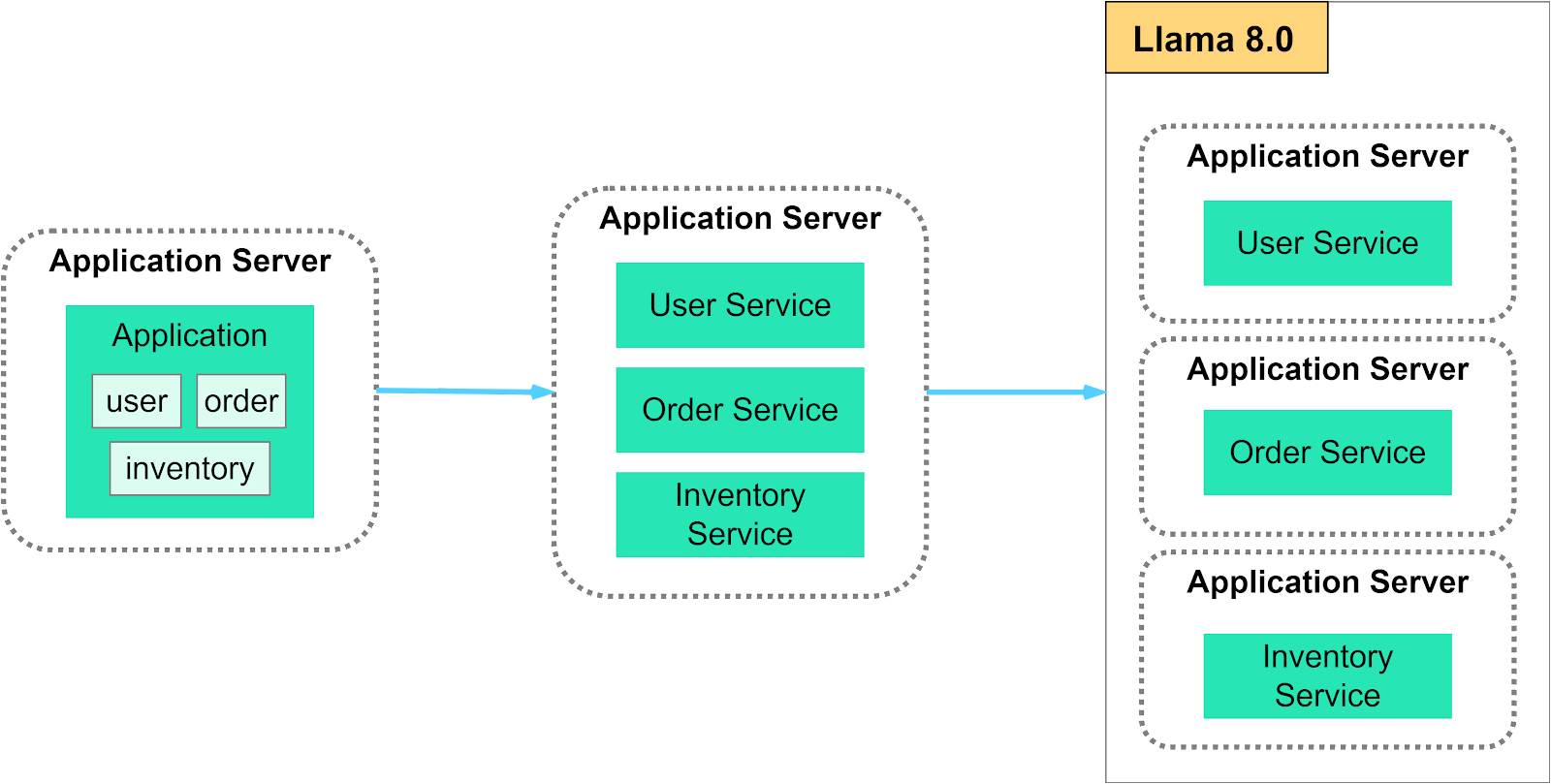
Over time, if the business keeps on growing and the company keeps on hiring developers, the service layer naturally evolves to be more granular. For example,
Different services may share a common function. It might be ideal to manage the common functions with a small team
Features and services are developed at different paces and deployed according to different release schedules
Microservice architecture structures an application as a collection of small, independent services, with each service running its own processes and communicating with each other through lightweight protocols like gRPC.
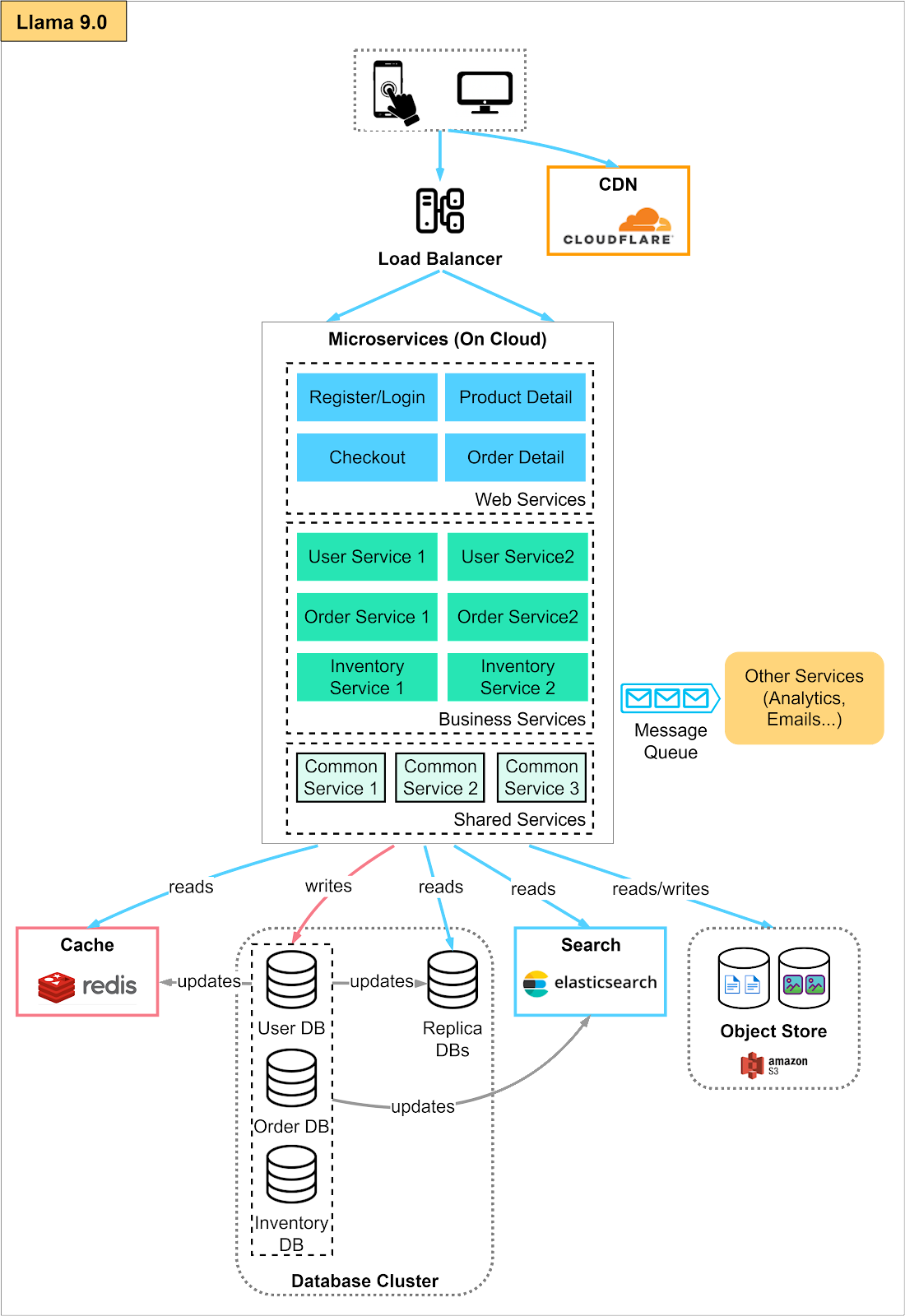
In our example, we split the services into a web layer where the services handle user requests from the client.
The web services forward the requests to the appropriate services in the business layer. Here we have user service, order service, and inventory service as examples.
It is worth noting that, in the microservice architecture, the databases tend to become service-specific and are managed by the specific teams that own those services. In our example, there could be a user database cluster, an order database cluster, and an inventory database cluster. Each could also be sharded if the request loads require that.
In a microservice architecture, it is also common to forward non-latency-critical requests to message queues. This decouples the latency-critical portion of the application from those that could be processed asynchronously.
Now we have a full-fledged microservice architecture. Overall, microservice architecture provides a way to break down a complex application into smaller, more manageable components, leading to increased development efficiency. This primarily solves an organizational problem, rather than a technical one.
This concludes the discussion of the second part. We'll resume next Wednesday.