In this four-part series, we'll discuss a typical architectural evolution of a website/app, and how/why we make technical choices at different stages.
Do we build a monolithic application at the beginning?
When do we add a cache?
When do we add a full-text search engine?
Why do we need a message queue?
When do we use a cluster?
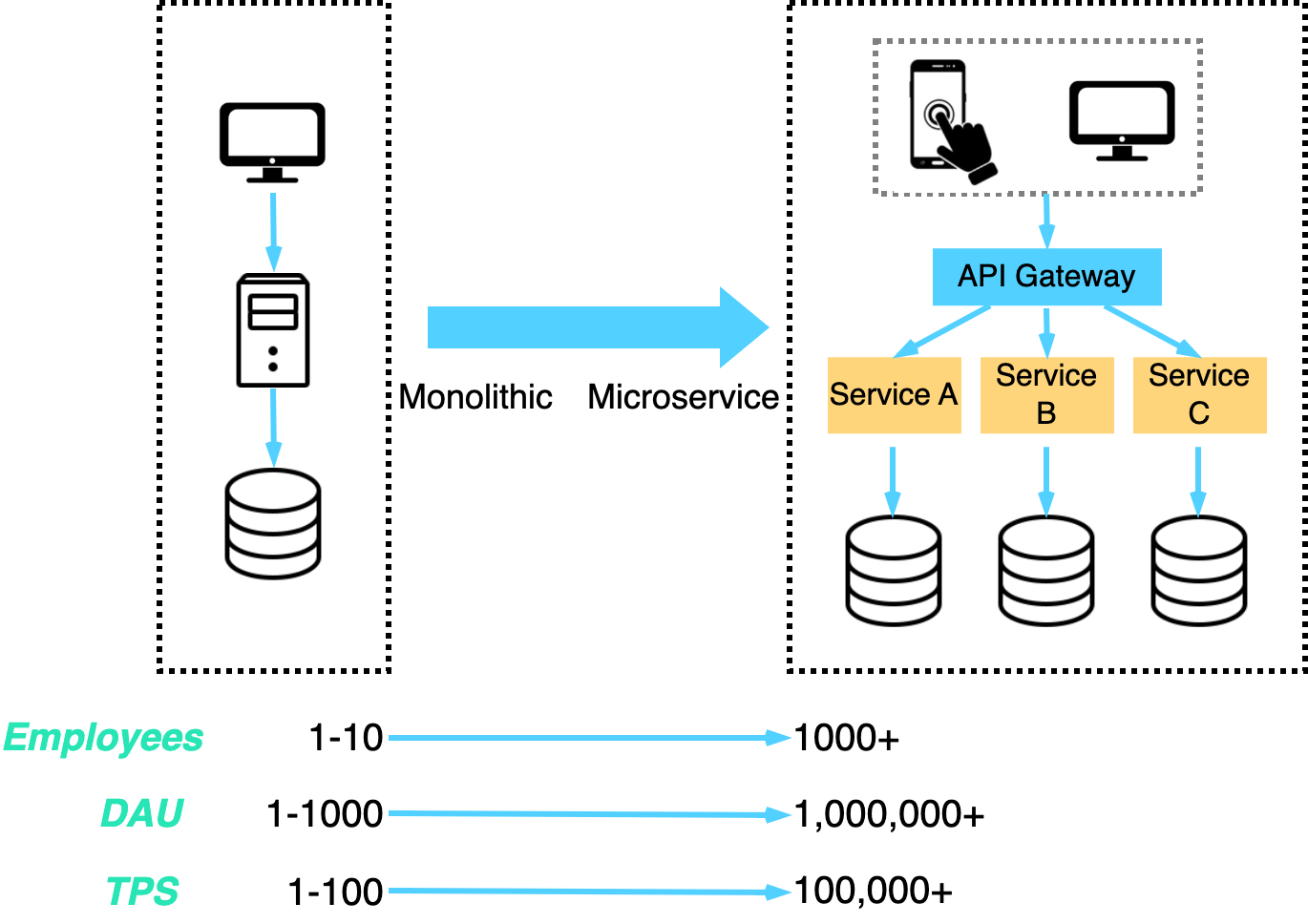
In the first two segments, we examine the traditional approach to building an application, starting with a single server and concluding with a cluster of servers capable of handling millions of daily active users. The basic principles are still relevant.
In the final two segments, we examine the impact of recent trends in cloud and serverless computing on application building, how they change the way we build applications, and provide insights on how to consider these modern approaches when creating your next big hit.
Let’s examine how a typical startup used to build its first application. This basic approach was common up until about 5 years ago. Now with serverless computing, it is much easier to start an application that could scale to tens of thousands of users with very little upfront investment. We will talk about how we should take advantage of this trend later in the series.
For now, we will dive into how an application (Llama) is traditionally built at the start. This lays a firm foundation for the rest of our discussion.
In this first architecture, the entire application stack lives on a single server.
The server is publicly accessible over the Internet. It provides a RESTful API to handle the business logic and for the mobile and web client applications to access. It serves static contents like images and application bundles that are stored directly on the local disk of the server. The application server is connected to the database which also runs on the same server.
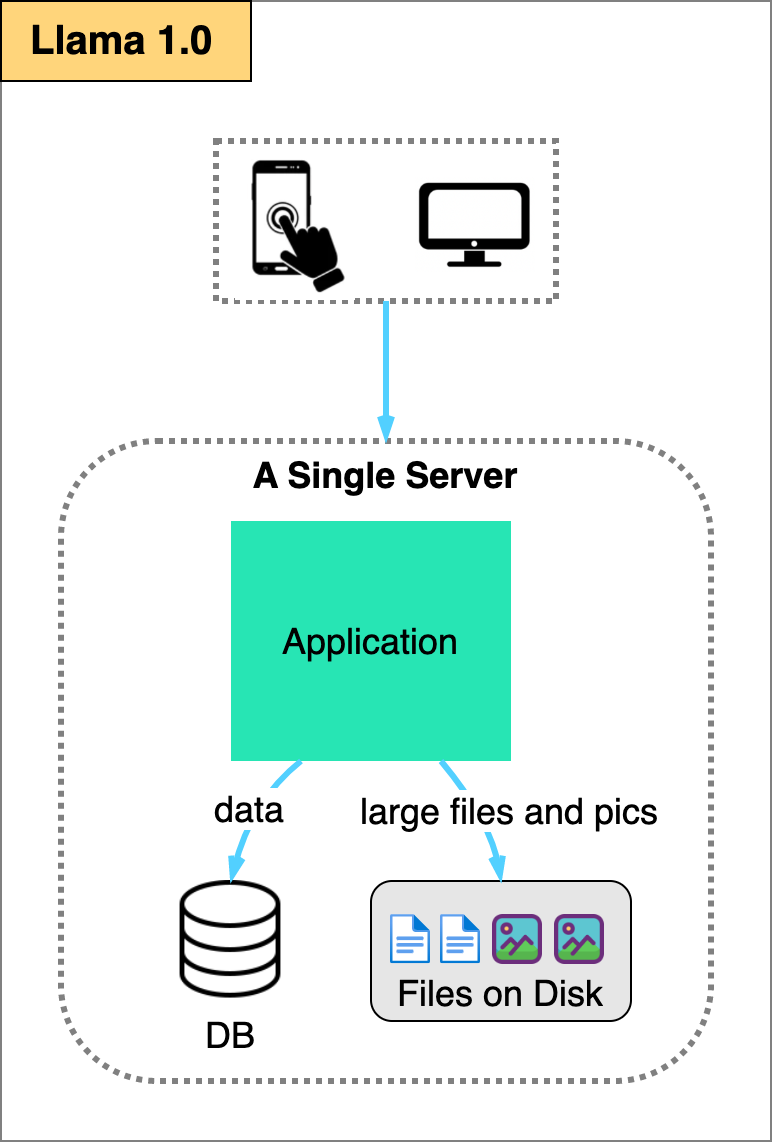
With the architecture, it could probably serve hundreds, maybe even thousands, of users. The actual capacity depends on the complexity of the application itself.
When the server begins to struggle with a growing user load, one way to buy a bit more time is to scale up to a larger server with more CPU, memory, and disk space. This is a temporary solution, and eventually, even the biggest server will reach its limit.
Additionally, this simple architecture has significant drawbacks for production use. With the entire stack running on a single server, there is no failover or redundancy. When the server inevitably goes down, the resulting downtime could be unacceptably long.
As the architecture evolves, we will discover how to solve these operational issues.
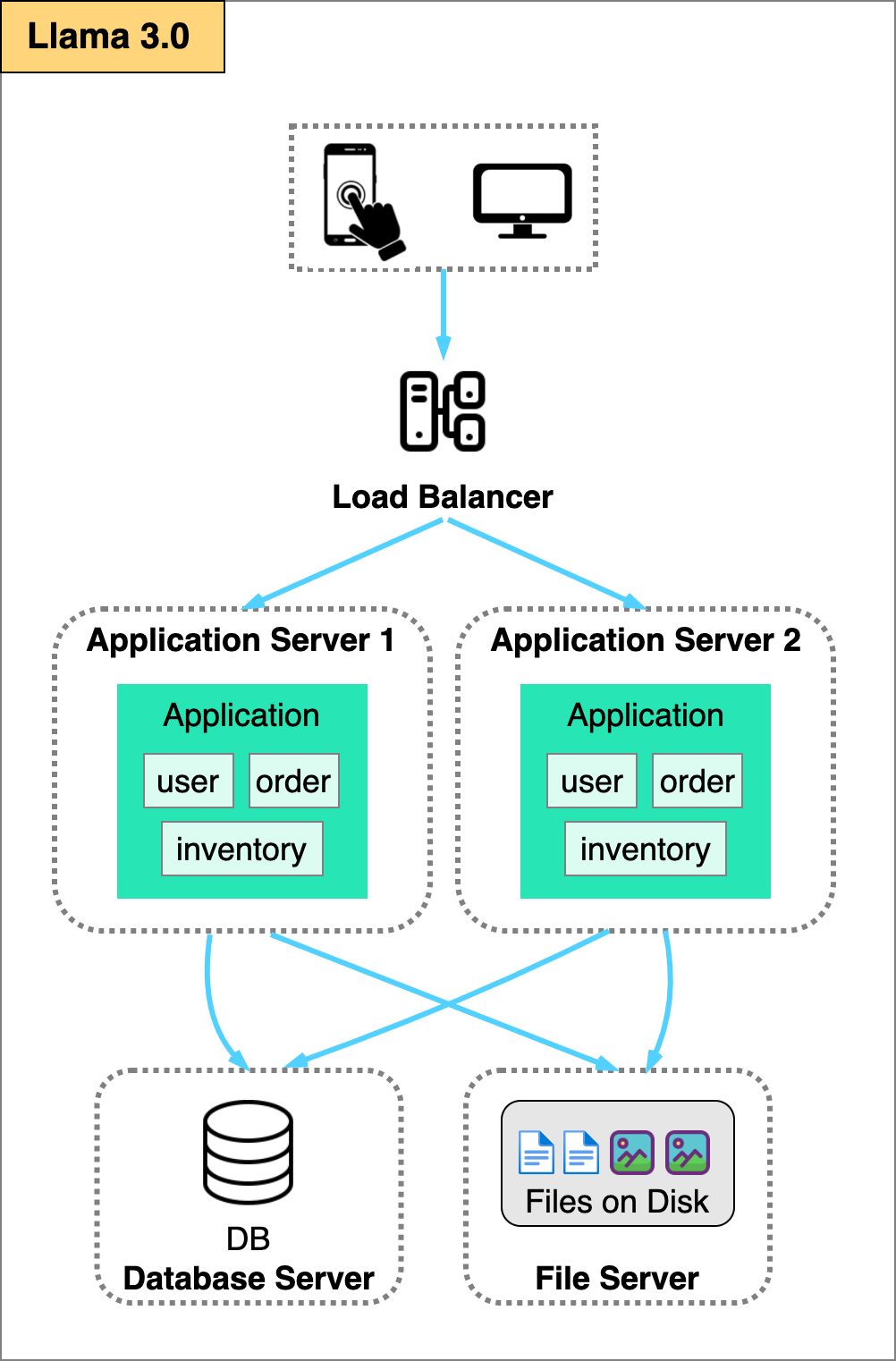
As we outgrow a single server, the next logical step is to separate it into many servers.
This is a form of horizontal scaling.
The first logical split is to move the database to its own server. For most applications, the database workload requires a different set of CPU, memory, and disk capacity than the application server. By separating the two, they can be independently tuned for their specific conditions.
Depending on the size of the static contents and the traffic volume served by the application, it might also make sense to store the static files on a dedicated file server.
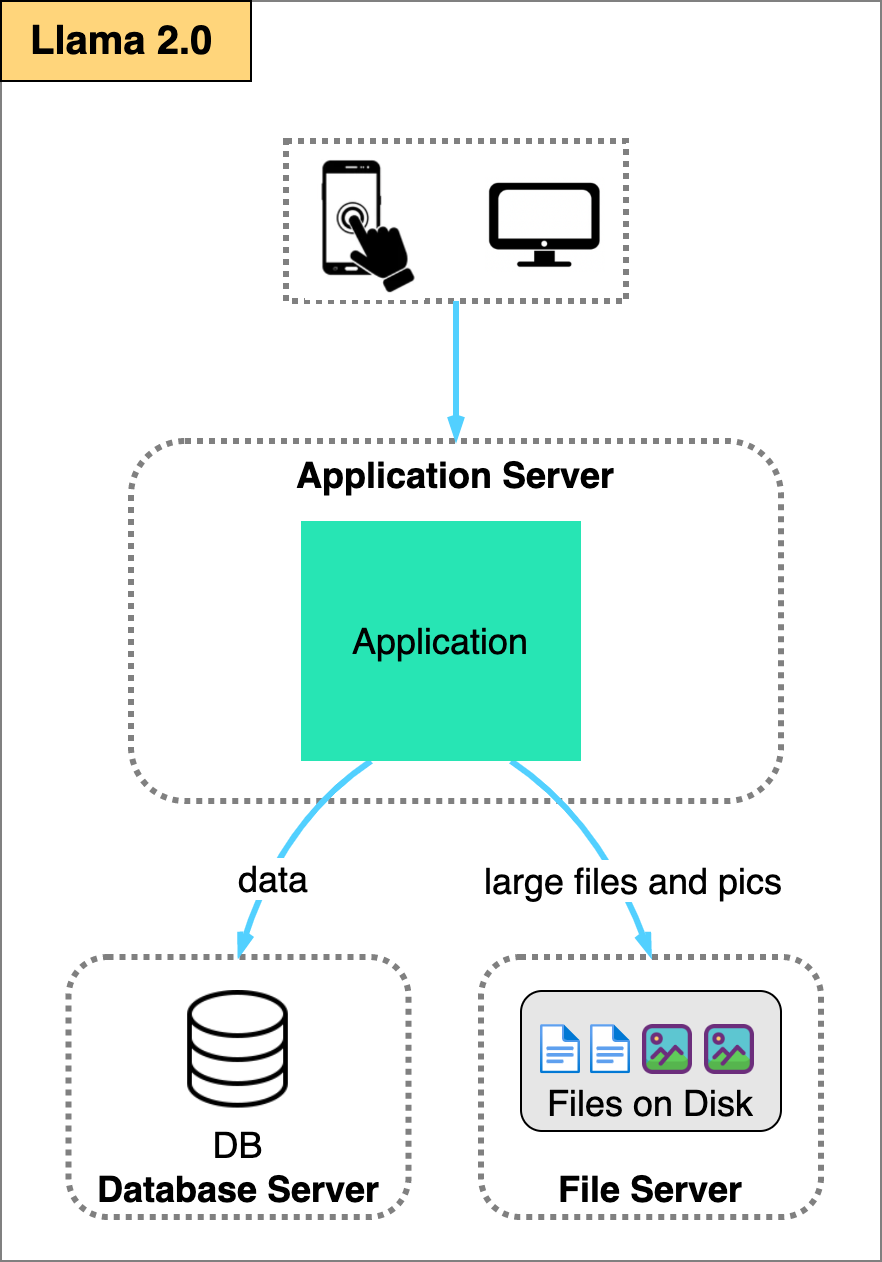
As traffic continues to grow, at some point the single application server will become overloaded.
Even if scaling up to a larger server is still viable, running the API tier on a single server is bad from an operational perspective. It is time to scale the API tier horizontally by introducing multiple application servers.
To accomplish this, we will put a load balancer in between the client applications and the application servers. The load balancer distributes loads from the clients across many application servers.
There are two common ways to distribute traffic to the application servers.
The first is round robin, a simple load-balancing algorithm that distributes incoming requests evenly across a group of application servers.
The second is called a sticky session, where requests from the same user are routed to the same application server for the duration of the user session.
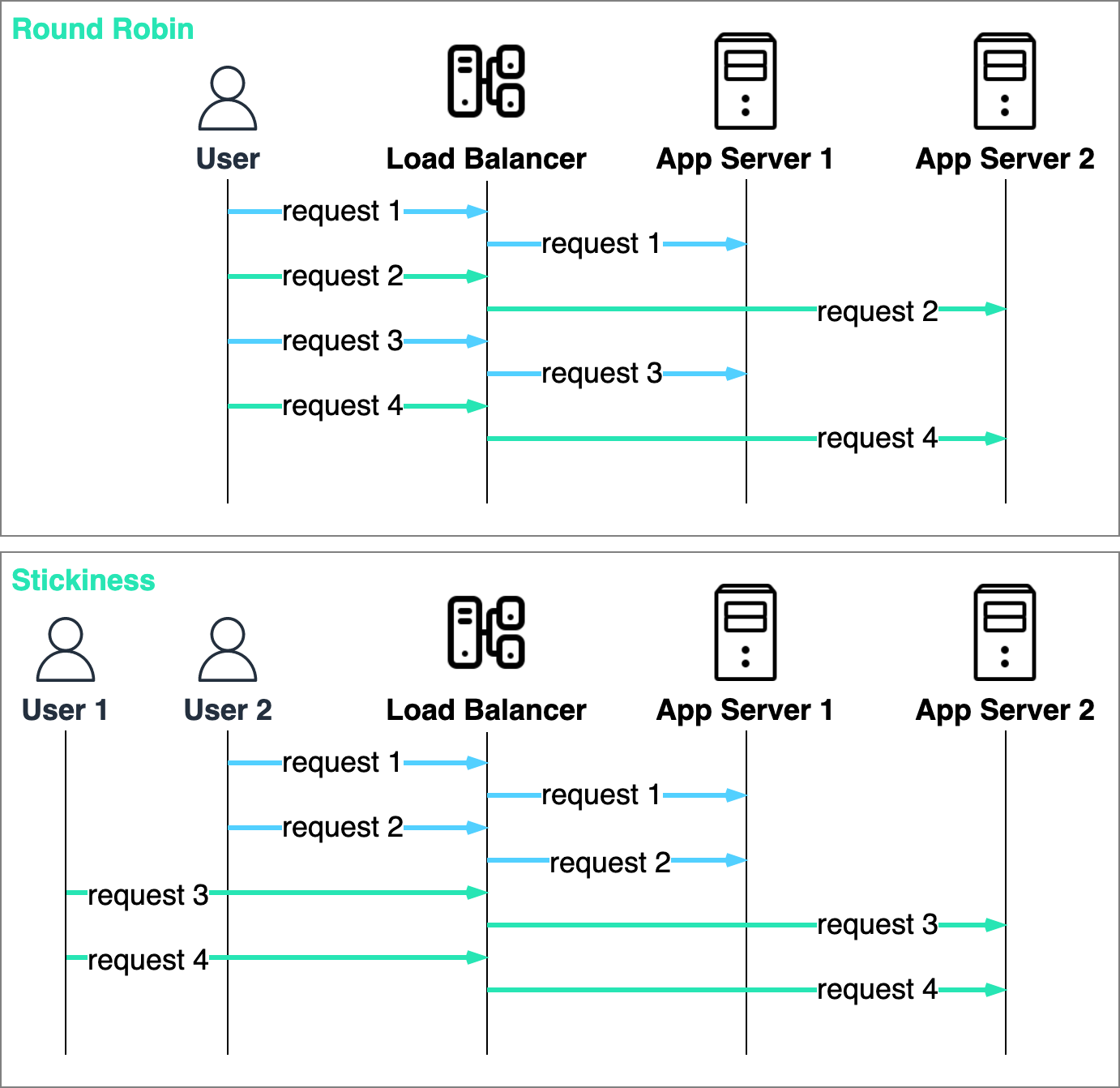
Sticky sessions should be avoided unless there is a strong technical reason to use them. This approach has a significant drawback as it can lead to an uneven distribution of load among application servers, resulting in some servers being overloaded while others are underutilized.
To use round-robin distribution, the user session data is stored in the database. On every request, the application server fetches the user session data from the database before processing the request. This allows the application servers to be stateless, providing greater resilience in the event of a server failure, as a stateless server can be easily replaced.
Load balancers have several other benefits worth mentioning.
They handle TLS termination, which simplifies the deployment of secure applications.
The load balancer tracks the health of individual application servers and automatically takes each one in and out of service based on its health, making software deployment non-disruptive from the user’s perspective.
With a load balancer in place, we can also benefit from failover and redundancy. If one application server fails, the load balancer automatically directs traffic to the healthy servers, providing high availability and resilience.
Scaling the application server brings extra complexity to load balancing. As we can see in the rest of the article, this is a common pattern: we solve one problem by introducing another.
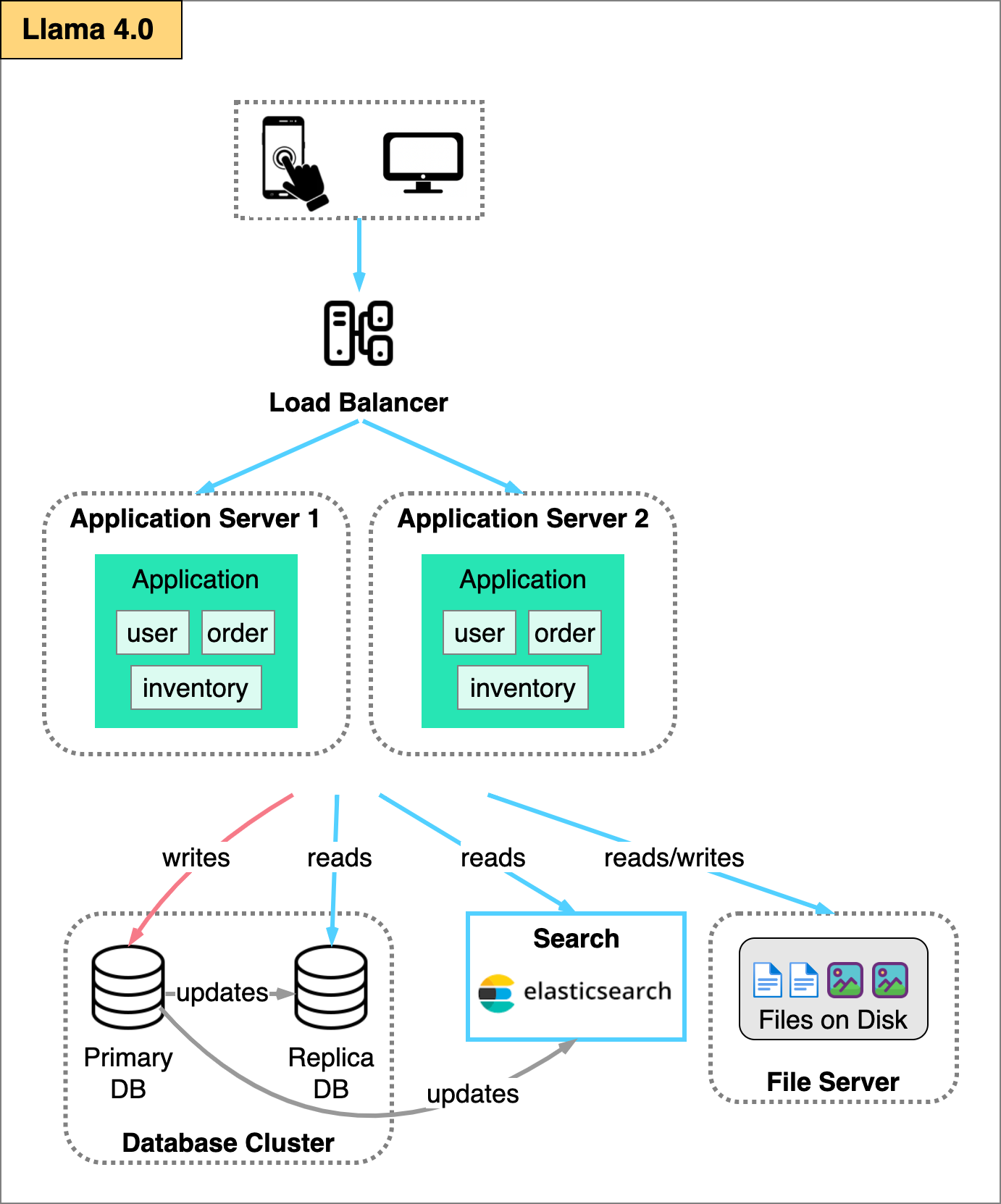
As we continue to scale, bottlenecks will start to appear. In most applications, the database is likely the first place to have issues.
In our fictitious startup, as we bring in more products to sell from more merchants, users start to experience delays when searching for products.
The bottleneck is in the database. It has trouble handling a massive number of read queries while writes occur frequently.
One relatively straightforward method to handle this bottleneck is called the primary-replica architecture.
With this method, we deploy a database cluster with a single primary database to handle writes and a series of read replicas to handle reads. We can have different replicas handle different kinds of read queries to spread the load.
The drawback of this approach is replication lag. Replication lag refers to the time difference between when a write operation is performed on the primary database and when it is reflected in the read replica.
When replication lag occurs, it can lead to stale or inconsistent data being returned to clients when they query the read replica.
Whether this slight inconsistency is acceptable is determined on a case-by-case basis, and it is a tradeoff for supporting an ever-increasing scale.
For the small number of operations that cannot tolerate any lags, those reads can always be directed at the primary database.
Another potential issue with relational databases that might impact some applications is the lack of fuzzy search support.
Fuzzy search allows for searching even if there are typos in the search term, which is useful for applications like online e-commerce, where allowing users to search for products without requiring the exact matching search term is critically important.
For these specific use cases, it is useful to replicate a subset of the dataset where such search capabilities are required for a full-text search engine like Elasticsearch.
This concludes the discussion of the first part. We'll resume next Wednesday.